

PyCaretとは
PyCaretとは、機械学習のモデル開発において、データの前処理や可視化、モデル開発を数行のコードで実現可能なPythonのAutoMLライブラリです。
PyCaretはいくつかの主要な機械学習ライブラリ(scikit-learn, XGBoost, LightGBMなど)をPythonでラッパーしており、分類や回帰、クラスタリング、異常検知、自然言語処理が扱えます。
この記事では「PyCaret」を用いて、「scikit-learn」付属のirisデータセットを利用し分類問題を実施します。
PyCaretをインストールする
普段利用しているPCにインストールする場合、ターミナルやコマンドプロンプトを開き、以下のコマンドでインストール出来ます。
pip install pycaretJupyter NotebookやGoogle Colabでは先頭に!をつけて以下のコマンドにてインストール出来ます。
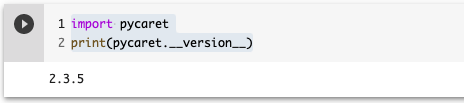
!pip install pycaretこの記事ではPyCaretのバージョンを2.3.5を用い、実行環境はGoogle Colabを用います。
必要なパッケージの読み込み
import warnings
# 不要な警告文非表示
warnings.filterwarnings("ignore")
from pycaret.classification import *
from sklearn.datasets import load_iris
import pandas as pdhttps://pycaret.readthedocs.io/en/latest/api/classification.html
データの読み込み
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.DataFrame(iris.target, columns=["target"])
df = pd.concat([X,y], axis=1)AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取る先頭5件表示
pandasのhead()で先ほど作成したデータフレーム(df)から先頭より5件を表示します。
df.head()前処理
setup()を使うと、欠損値処理、データ分割などを行なってくれます。
targetには、目的変数を渡します。
exp1 = setup(df, target = 'target')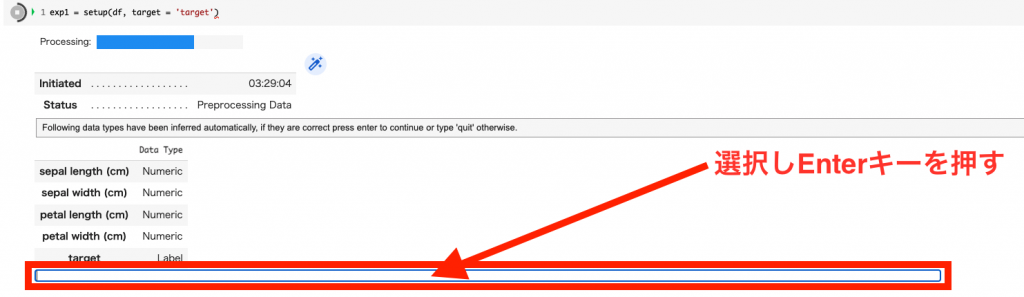
モデルを比較する
モデルの比較はcompare_models()を使います。(※ 末尾に「s」をつける必要があります)
compare_models()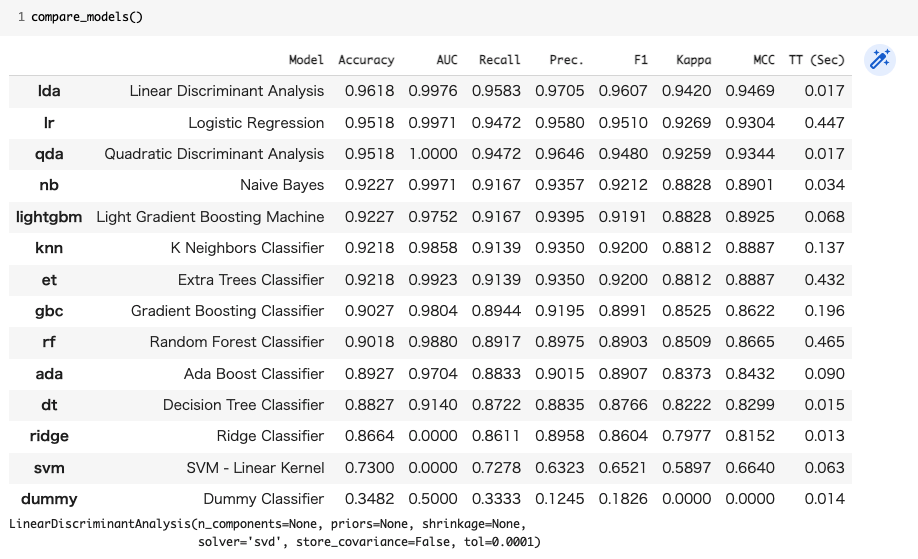
モデリング
今回は、「Accuracy(正解率)」が最も高い「lda(Linear Discriminant Analysis)」でモデルを作成します。
出力される表の「Model」列に比較するモデル手法の名前が記載されています。
model = create_model('lda')モデルのチューニング
下記のコードでモデルのハイパーパラメータのチューニング(最適化)を実行します。
tuned_model = tune_model(model, optimize = 'Accuracy')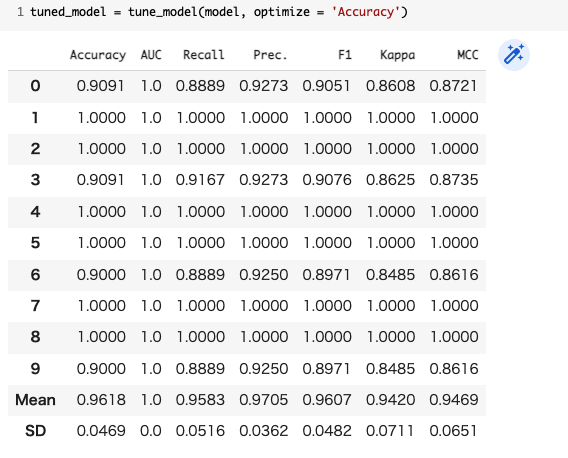
ハイパーパラメータの確認
# モデルの評価指標を確認
evaluate_model(tuned_model)
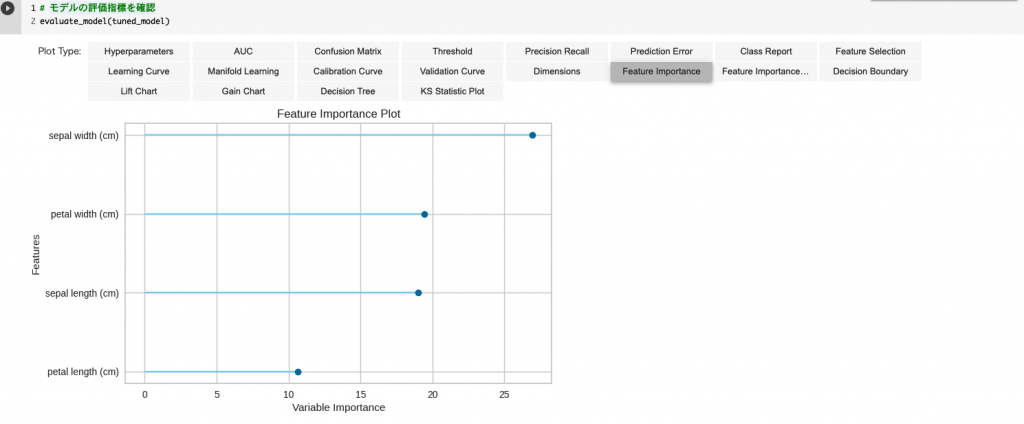
特徴量の重要度の算出
「Feature Important」を選択すると、各特徴量がどの程度予測と関連しているか可視化できます。
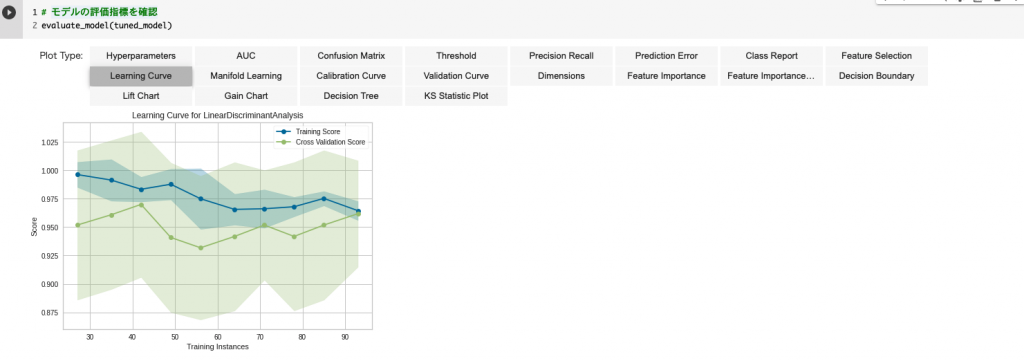
学習曲線を確認する
「Plot Type」の「Learning Curve」を選択すると、学習曲線を可視化できます。
学習用データとテスト用データの予測精度がデータ数に対しどの程度推移しているか確認できます。
作成したモデルの読み込み
finalize_model()で作成したtuned_modelを読み込みます。
final_model = finalize_model(tuned_model)予測
predict_model()で予測できます。
pred = predict_model(final_model, data = X)機械学習を効率よく学ぶには?
この記事では「PyCaret」を用いて機械学習の一連のプロセス(モデルの比較検討やモデル作成等)が簡単に数行のコードでできました。
もっと深く機械学習を学びたいという方は、データサイエンティストや機械学習エンジニアに質問し放題かつ、データ分析の基礎から実践まで、体系的に学べる動画コンテンツでデータ分析技術を学びたい方は、オンラインで好きな時間に勉強できるAI Academy Bootcampがオススメです。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!
[…] またPythonのAutoMLライブラリの1つである「PyCaret」などもあります。 […]