

この記事は約8分で読めます。(※コードを確認しながら読む場合は15分程度)
この記事でわかること
・Webスクレイピングの主な活用方法と実用例
・実装前に確認すべき法的リスクとマナー
・PythonとGoogle Chromeで始める環境構築 / BeautifulSoupとCSSセレクタを使ったデータ抽出の手順
AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取るはじめに
Webスクレイピングとは、Web上の情報を自動で取得・整理する技術です。マーケティングや業務効率化に役立つ、実用性の高いスキルです。
PythonとGoogle Chromeがあれば、すぐに始めることができます。この記事では、基本の使い方と注意点をコード付きでわかりやすく解説します。
*この記事では、Webブラウザ(Google Chrome)を使って解説していきます。ブラウザが異なる場合正しく動作しない場合がありますので、事前にダウンロードを済ませてからこのテキストを進めてください。
Google Chromeダウンロード
スクレイピングとクローリングの違い
Web上の情報を収集する技術には、「スクレイピング」と「クローリング」の2つがあります。似たように見えますが、その目的と役割には明確な違いがあります。
スクレイピングは、特定のWebページから必要な情報を抽出する技術です。たとえば、商品名や価格、ニュース記事の見出しなど、明確に取得したい要素がある場合に使われます。
クローリングは、Webサイト全体を巡回して情報を収集するプロセスを指します。複数ページを自動でたどっていき、対象となるデータをまとめて取得するのが特徴です。
クローリングを行うプログラムは「クローラー(crawler)」や「スパイダー(spider)」とも呼ばれます。検索エンジンがWebの情報を収集する際にも、この技術が使われています。
つまり、クローリングが“情報を探す役”だとすれば、スクレイピングは“情報を取ってくる役”と考えるとイメージしやすいでしょう。
Webスクレイピングの主な活用事例
スクレイピングは単なる「データの取得手段」ではありません。活用の仕方によって、ビジネスにも開発にも幅広く応用できます。ここでは、代表的な3つの活用シーンを紹介します。
1. マーケティングデータの収集
ニュースサイトやSNS、株価の動きなど、日々変化する情報を自動で収集できます。たとえば競合サイトの価格情報を定期的に取得することで、市場動向の分析や価格戦略の見直しに活用できます。
2. 業務の効率化
繰り返し行っている情報収集の作業を自動化するだけで、作業時間を大幅に削減できます。例としては、Twitterで特定のキーワードを含む投稿を毎日自動で取得したり、求人情報やイベント告知を一括で集めたりといった活用が考えられます。
3. サービスやアプリケーション開発
検索エンジンのように定期的に情報を蓄積し、ユーザーに提供するサービスの基盤としても使えます。たとえば、不動産情報の一括表示アプリや、特定サイトの新着情報通知システムなどが実現可能です。
Webスクレイピングを始める前に知っておきたい法的リスクとマナー
スクレイピングを始める前に、必ず確認しておきたいのが法的なリスクとマナーです。便利な技術だからこそ、行為内容によっては、違法行為になってしまうケースもあります。
1. APIの有無を確認する
対象のWebサービスが公式にAPIを提供している場合は、まずAPIの利用を検討しましょう。APIは提供者が意図して設計した情報取得手段です。スクレイピングよりも安定していて、利用規約にも準拠しやすい利点があります。
2. 著作権の配慮
Web上の情報は、誰かの著作物である可能性があります。利用目的によっては、以下のような著作権に関する規定に注意が必要です。
私的利用のための複製(第30条)
情報解析のための複製等(第47条の7)
※2019年1月1日の改正著作権法により、この47条の7が廃止され、新しい条文である新30条の4や新47条の5が発効します。詳しくは下記記事をご確認ください。
進化する機械学習パラダイス ~改正著作権法が日本のAI開発をさらに加速する~
特に問題となる3つの権利として以下が挙げられます。
・複製権(第21条)…著作物をコピー・保存する権利
・翻案権(第27条)…著作物を編集・翻訳・変形する権利
・公衆送信権(第23条)…取得したデータをネット上で公開する権利
1) 複製権
複製権は、著作権に含まれる権利のひとつで、著作権法第21条で規定されています。
(第21条「著作者は、その著作物を複製する権利を専有する。」)
複製とは、作品を複写したり、録画・録音したり、印刷や写真にしたり、模写(書き写し)したりすること、そしてスキャナーなどにより電子的に読み取ること、また保管することなどを言います。
引用先: https://www.jrrc.or.jp/guide/outline.html
2) 翻案権
翻訳権・翻案権は、著作権法第二十七条に規定されている著作財産権です。
第27条では「著作者は、その著作物を翻訳し、編曲し、若しくは変形し、又は脚色し、映画化し、その他翻案する権利を専有する」(『社団法人著作権情報センター』より)と明記されています。
反対に見ると、これらを著作者の許諾なしに行うと、著作権の侵害になるということです。
引用先: http://www.iprchitekizaisan.com/chosakuken/zaisan/honyaku_honan.html
3) 公衆送信権
公衆送信権は、著作権法第二十三条において規定される著作財産権です。
この第23条では「著作者は、その著作物について、公衆送信(自動公衆送信の場合にあっては、送信可能化を含む。)を行う権利を占有する。」
「著作者は、公衆送信されるその著作物を受信装置を用いて公に伝達する権利を占有する。」と明記されています。
引用先: http://www.iprchitekizaisan.com/chosakuken/zaisan/kousyusoushin.html
これらを侵害してしまうと、思わぬ法的トラブルに発展する可能性があります。特に、収集したデータを外部公開・商用利用する場合は注意が必要です。
3. サーバーへの負荷とモラル
スクレイピングのコードは、対象のWebサイトに繰り返しアクセスします。アクセス頻度が高すぎると、サーバーに負荷をかけたり、迷惑行為と見なされたりする恐れがあります。実際、過剰なアクセスが原因で逮捕者が出た「岡崎市立中央図書館事件」のような例もあります。
適切なインターバルの設定や、robots.txtの内容を確認するなど、基本的なマナーを守ることが求められます。
以上を踏まえた上で、次に進んでいきましょう。
今回ターゲットとするWebサイトは、こちら側が用意したサーバーのWebサイトからスクレイピングして行きます。
クローラーを作成するために必要なライブラリ
Pythonをベースに説明します。
・「urllib」もしくは「Requests」 HTTPライブラリ
・BeautifulSoup HTMLの構造を解析するライブラリ
・Scrapy Webスクレイピングフレームワーク
場合によっては、PhantomJSもしくはSeleniumを使う場合もあります。
スクレイピングの基本手順
大きく分けると3つ手順を行う必要があります。
1.Webページを取得する
2.スクレイピングする
3.抽出したデータを保存する
この3つの手順を行うことで、データを収集することが可能になります。
HTMLとCSS
スクレイピングをするにあたって、HTMLとCSSに関しての基本を知っておくと便利です。HTMLとはHyperText Markup Languageの略で、Webページを作成するためのマーク アップ言語の1つです。CSS(Cascading Style Sheets)とは、HTML文書の装飾やレイアウトをつくるための言語です。Webページは「文章の構造を定義するHTML」と「デザインを指定するCSS」のセット」で基本的に、作られています。また、これら2つはプログラミング言語ではなく、また別のものだと考えてください。以下は、HTMLとCSSのコードです。
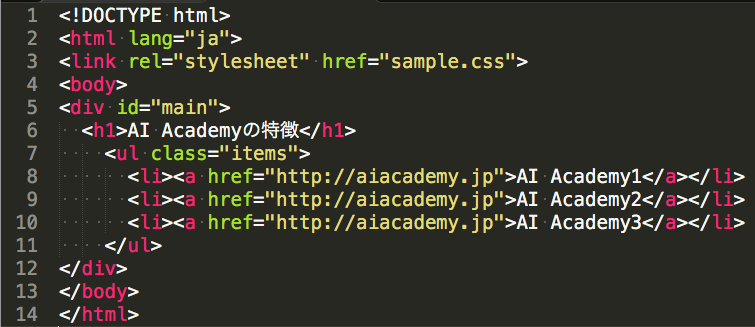
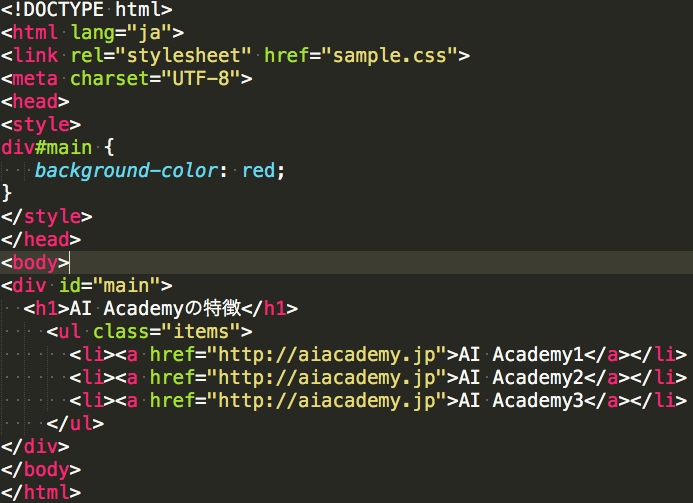
ちなみに、sample.htmlとsample.cssは通常は上記のように分けられますが、
以下のように1つのファイルにHTMLとCSSを記述することもできます。
Webサイトからデータを取得しよう
まずは、Pythonを使いWebサイトからデータを取得する方法を紹介します。
ここでは、Pythonに標準で用意されている「urllib」というライブラリを使います。
・urllib
URLを扱うモジュールを集めたライブラリです。
urllib.requestモジュールにある、urlretrieve()関数を使うことで、直接ファイルを取得できます。
# ※このコードはurlretrieve関数に渡す引数に関しての構文です。この1行だけでは動作しません。
urllib.urlretrieve(url[, filename[, reporthook[, data]]])
まずはじめに、AI AcademyのWebページから、画像データを取得してみましょう。
import urllib.request
imgname = "logo_courses_ai.png"
url = "https://aiacademy.jp/assets/images/" + imgname
urllib.request.urlretrieve(url, imgname)
print("done.")
次に、urlopen()を使い、特定のサイトの全HTMLコードを出力してみましょう。
# ※このコードはurlopen関数に渡す引数に関しての構文です。この1行だけでは動作しません。
urllib.urlopen(url[, data[, proxies[, context]]])
コードは下記のようになります。
from urllib.request import urlopen
html = urlopen("https://aiacademy.jp")
data = html.read()
decoded_data = data.decode('utf-8')
print(decoded_data)
Pythonのurllibモジュールを使うことで、画像の取得や、HTMLデータの取得ができます。
Requests
Pythonには他にも先ほど紹介したHTTPライブラリのurllib以外にもRequestsというライブラリもあります。
Requestsの扱いなどは公式ドキュメントか、AI Academyのテキストをご確認ください。
# GETリクエスト
import requests
res = requests.get("https://aiacademy.jp")
print(res) # <Response [200]>
print(res.text) # 帰って来たレスポンスボディをテキスト形式で取得
BeautifulSoupでスクレイピングする
Beautiful Soupはインストールは下記コマンドでインストール可能です。
pip install bs4
上記のインストールコマンドはMacの方はターミナル、Windowsの方はコマンドプロンプトで実行します。
さて、まずはfind()メソッドから見ていきましょう。
find()メソッドを利用することで、任意のid属性を指定し要素を見つけることが出来ます。
Beautiful Soup日本語ドキュメント
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://aiacademy.jp/assets/scraping/sample1.html")
data = html.read()
html = data.decode('utf-8')
# HTMLを解析
soup = BeautifulSoup(html, 'html.parser')
# 解析したHTMLから任意の部分のみを抽出(ここではtitleとbody)
title = soup.find("title")
body = soup.find("body")
print("title: " + title.text)
print("body: " + body.text)
find_all()メソッド
find_all()を使うと、複数の要素(タグ)を一気に取得することが出来ます。
また、find_all()にはキーワード引数を指定することが可能です。
キーワード引数にidに値を渡すとタグの’id’属性に対して取得可能です。
soup.find_all(id=’ID名’)
soup.find_all(‘タグ’, class_=”クラス名”)でクラスの特定のタグに対して取得できます。
find_all()ドキュメント
from bs4 import BeautifulSoup
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://aiacademy.jp/assets/scraping/sample2.html")
data = html.read()
html = data.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all("a")
for a in links:
href = a.attrs['href']
text = a.text
print(text, href)
CSSセレクタ
CSSセレクタの説明に入る前に少し、「CSS」と「セレクタ」に関して説明します。
まず、CSSの基本的な書き方は次の通りです。
セレクタ {
プロパティ:値;
}
セレクタとは一言でいうと、スタイルを適用する対象のことです。
セレクタには、「HTMLの要素」、「class名(プログラミングのクラスではありません)」、「ID名」の3つがセレクタの基本セレクタです。
他にもセレクタの種類はいくつかあります。
CSSセレクタ
CSSセレクタ
スクレイピングをする際に、CSSのセレクタを指定して、任意の要素を抽出することが出来ます。
メソッド
# これは記述例ですので、このままだと動きません。
soup.select_one(セレタク) CSSセレクタで要素を1つ取り出す
soup.select(セレクタ) CSSセレクタで複数要素を取り出しリスト型で返す
次のプログラムはCSSセレクタを使ったサンプルプログラムです。
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://aiacademy.jp/assets/scraping/sample3.html")
data = html.read()
html = data.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
h1 = soup.select_one("div#main > h1").string
print("h1: ",h1)
li_list = soup.select("div#main > ul.items > li")
for li in li_list:
print("li: ", li.string)
スクレイピングのためのChrome開発者ツール入門
スクレイピングを行うには、HTMLの構造解析が必要になります。
そこで、今回は、Google Chromeの開発者ツールを使います。
まず対象のサイトへアクセスし、右クリックをすると、画像のようなポップアップが開きます。
そこで一番下にある『検証』を押します。
検証を押すと次のような画面が表示されます。
さて、今後スクレイピングを行うにあたり、この開発者ツールを使っていきます。
※画像の文字が現在のページと異なっている場合がございます。
cssセレクタでスクレイピング実践
では、AI Academy Gymにアクセスし、『本気でAIエンジニアに
なりたい人向けのパーソナルジム』という文を、cssセレクタでスクレイピングして見ましょう。
from bs4 import BeautifulSoup
from urllib.request import urlopen
target_url = "https://aiacademy.jp/gym"
html = urlopen(target_url)
data = html.read()
html = data.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
data = soup.select("body > div > section.p-top-firstView > div.p-top-firstView__wrap > div > div > h2")
print(data[0].text)
次の6つのSTEPでCSSセレクタを取得可能です。
1. STEP1 開発者ツールで検証を開く。
2. STEP2 開発者ツール矢印ボタンを押して青色にする。
3. STEP3 青色にしたら、取得したい部分を選択しクリックする。
4. STEP4 青色ラインが引かれるので、左の白の・・・を選択する。
5. STEP5 copy > Copy selectorを押すとクリップボードにコピーされる。
6. STEP6 貼り付けする。
それでは順番に見ていきましょう。
- STEP1 開発者ツールで検証を開く。
- STEP2 開発者ツール矢印ボタンを押して青色にする。
- STEP3 青色にしたら、取得したい部分を選択しクリックする。
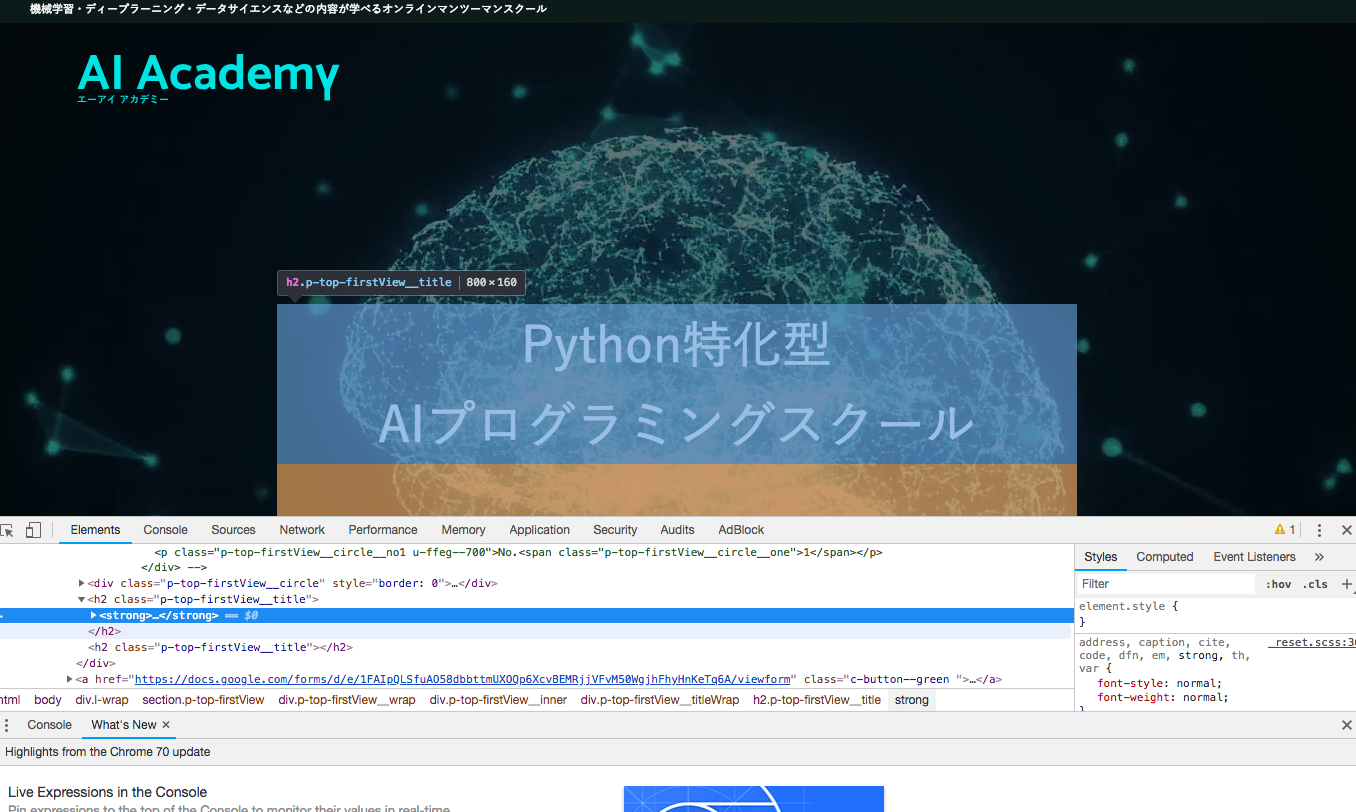
- STEP4 青色ラインが引かれるので、左の白の・・・を選択する。
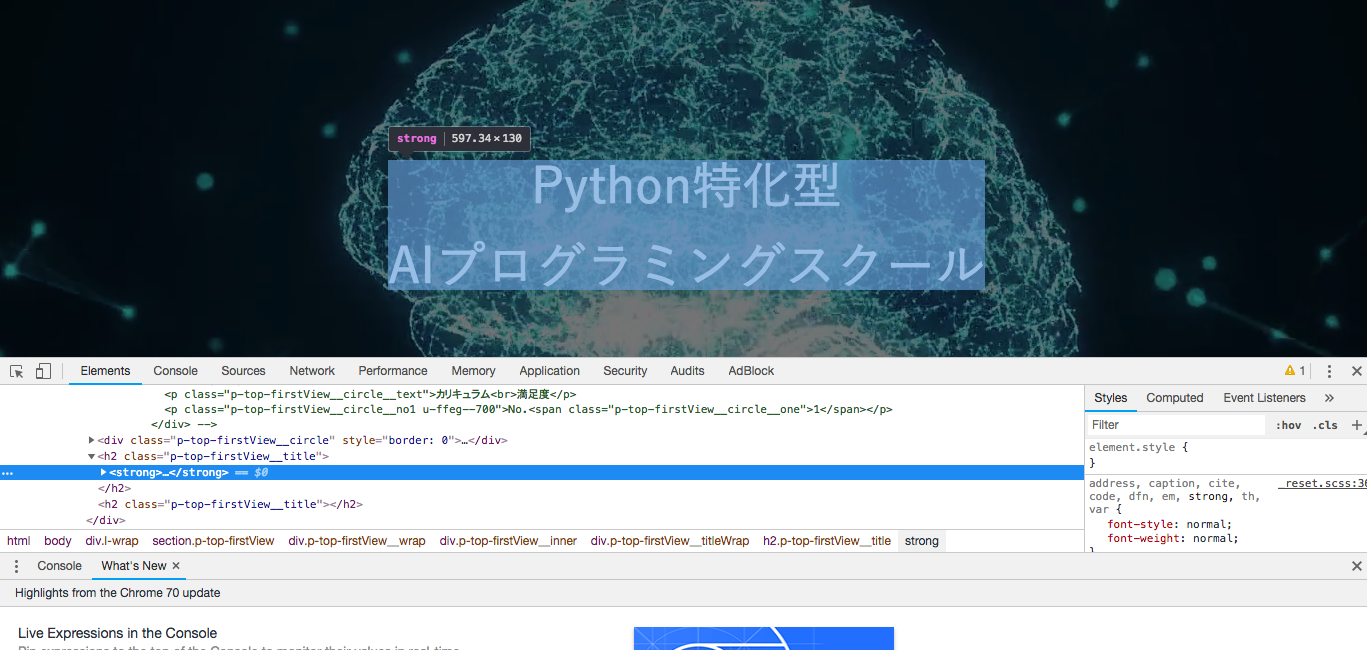
- STEP5 copy > Copy selectorを押すとクリップボードにコピーされる。
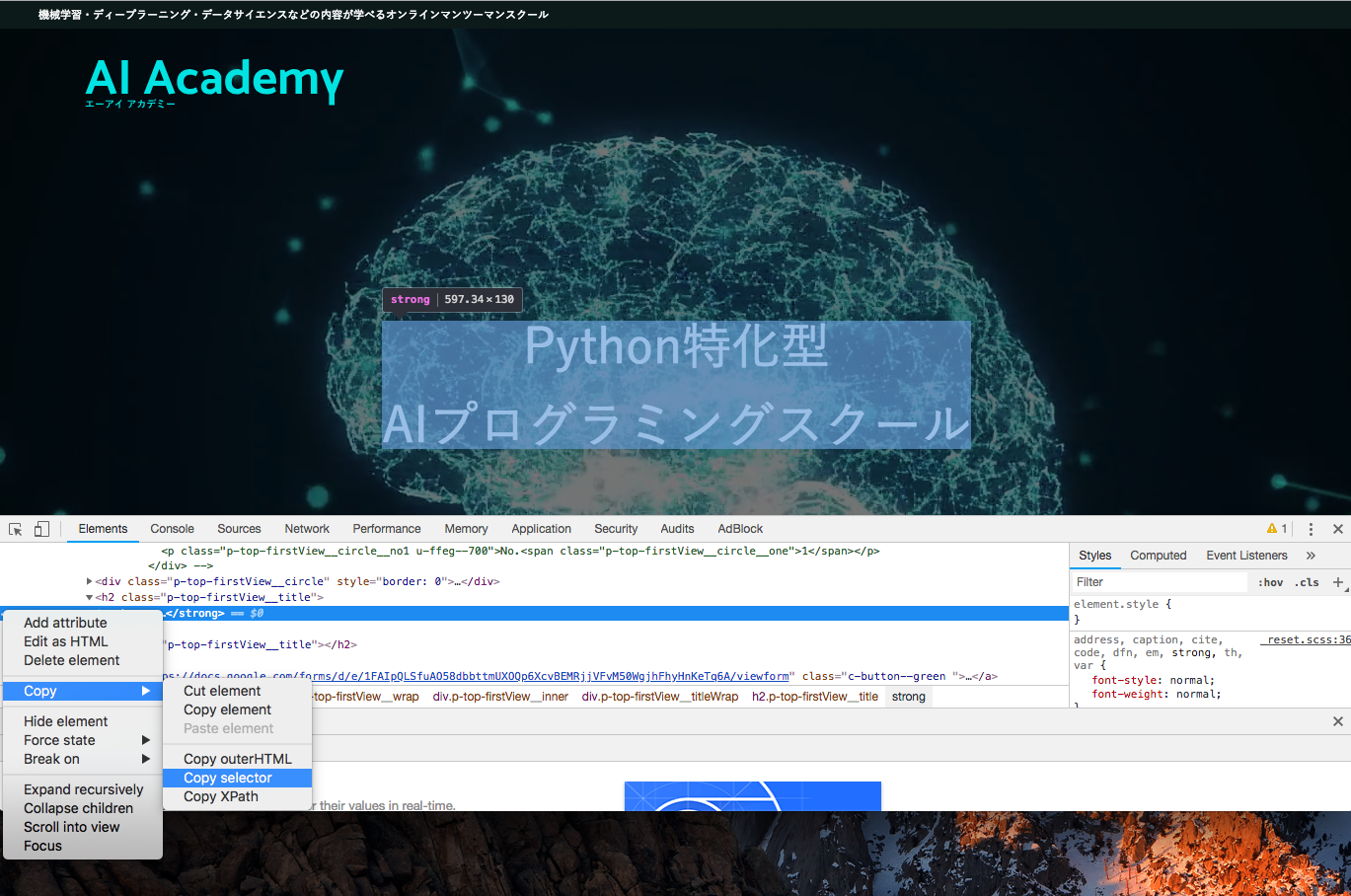
- STEP6 貼り付けする。
貼り付けすると次のようなコードが貼り付けられます。
body > div > section.p-top-firstView > div.p-top-firstView__wrap > div > div > h2:nth-child(2) > strongこれがcssセレクターです。
また、cssセレクタをコピーした際に、今回のように、nth-child(2)といったような書式を見ます。
その場合、BeautifulSoupはnth-childの記述方法に対応していないため、nth-of-typeを使いましょう。
nth-child(n)というのは、n番目の子となる要素を意味しております。
nth-of-type(n)はn番目のその種類の要素という意味でこちらを使えば取得可能です。
ですので、次のようにします。
body > div > section.p-top-firstView > div.p-top-firstView__wrap > div > div > h2:nth-of-type(2) > strong
ですが、今回この状態のCSSセレクタでプログラムを実行すると、何も取得できないため、次のようにします。
body > div > section.p-top-firstView > div.p-top-firstView__wrap > div > div > h2
このように、セレクタをそのままとってもうまくとれない場合がありますが、セレクタを多少修正する必要があるとはいえ、目視でセレクタを取得するよりChromeの検証ツールを使うことで簡単に必要なセレクタを取得できます。
まとめ
PythonとGoogle Chromeを使えば、Webスクレイピングはすぐに始められます。情報の自動収集は、マーケティングや業務効率化にも大きな力を発揮します。
一方で、法的なルールやマナーも理解しておくことが欠かせません。「できること」と「していいこと」は、常に意識しておく必要があります。
基本の技術と考え方を押さえて、安心してスクレイピングを活用していきましょう。
関連記事」:Pythonで画像データをスクレイピング 手軽に画像収集したい方必読!
Webスクレイピングに関するよくある質問
Q1. Python初心者ですが、スクレイピングは始められますか?
はい。基本的な文法とライブラリの使い方を学べば、数行のコードで情報を取得できます。この記事のコードを試すだけでも十分に入門になります。
Q2. スクレイピングは違法ではないのですか?
違法ではありませんが、著作権や利用規約を侵害するような使い方は問題になります。APIの有無やrobots.txtの内容を確認し、常識の範囲で利用しましょう。
Q3. 動的に生成されるサイトのデータは取得できますか?
可能です。JavaScriptによって表示される情報を取得したい場合は、Seleniumなどのブラウザ操作ツールを使う必要があります。
Q4. 実務で使うには、どこまで学ぶべきですか?
定期実行や大量データの保存、例外処理などを組み合わせていくことが求められます。初級を抜けたら、ScrapyやSeleniumの学習を進めてみましょう。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!

