

このサイトは、Pythonや生成AIなどを学べるオンラインプログラミングスクール AI Academy Bootcampが運営しています。
最短ルートで
生成AIを使いこなしたい方へ
- 生成AIを使ってみたが、思うような
結果が出ない - 生成AIの活用方法がわからない
- AIを使って業務を効率化したい
生成AIコース無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- 理解度を記録して進捗管理できる!
- テキストの重要箇所にハイライトを
残せる!
1分で簡単!無料!
無料体験して特典を受け取る分類と回帰に使える評価方法
最後に、分類でも回帰でも使える評価方法の交差検証とグリッドサーチについて説明します。
2つの手法の意味は以下の通りです。
・交差検証(Cross-validation):個々のモデルの汎化性能を評価する手法
・グリッドサーチ(grid search):機械学習のハイパーパラメータ探索の方法
それでは、一つずつ詳細を見ていきましょう。
ホールドアウト法
ホールドアウト法は、モデルを作る学習データと、モデルを評価するテストデータに分割して評価します。
データを分けることで、汎化性能(未知のデータに対する性能)を向上させることができます。
もし、未知のデータを予測するにあたり全てのデータを学習データにしてしまうと、過学習(学習データにだけ適合していて未学習のデータに対して正しく答えを出力できない状態)してしまいます。
scikit-learnのtrain_test_split()を使うことでデータを分けることが可能です。
細かい設定により分割する割合を変えることが出来ますが、何も設定しない場合、トレーニングデータには75%、テストデータは25%で分割されます。(test_sizeが25%にデフォルトで設定されています。)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris() # アイリスの花のデータセットの読み込み
x = iris.data # 全体は150個
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y) # データをトレーニング用とテスト用に分割
# (test_size=テストサイズの数を引数に渡すことで、テストサイズを調整可能です)
print(len(x_train)) # 112 (全体の75%がトレーニングデータに分割)
print(len(x_test)) # 38 (全体の25%がテストデータに分割)
交差検証(クロスバリデーション)
交差検証(cross-validation)とは、汎化性能を評価する統計的な手法で、分類でも回帰でも用いることができます。
機械学習を行うとき、学習を行うための学習データと未知のデータに適用したときのモデルを評価するためのテストデータがあります。
トレーニングデータでの性能がとても良いのにもかかわらず、テストデータでの性能が悪くなってしまうことを過学習と言います。
交差検証の中でも、よく利用されるK-分割交差検証について説明します。
K-分割交差検証は、データをK個に分割してそのうち1つをテストデータに残りのK-1個を学習データとして正解率の評価を行います。
これをK個のデータすべてが1回ずつテストデータになるようにK回学習を行なって精度の平均をとる手法です。
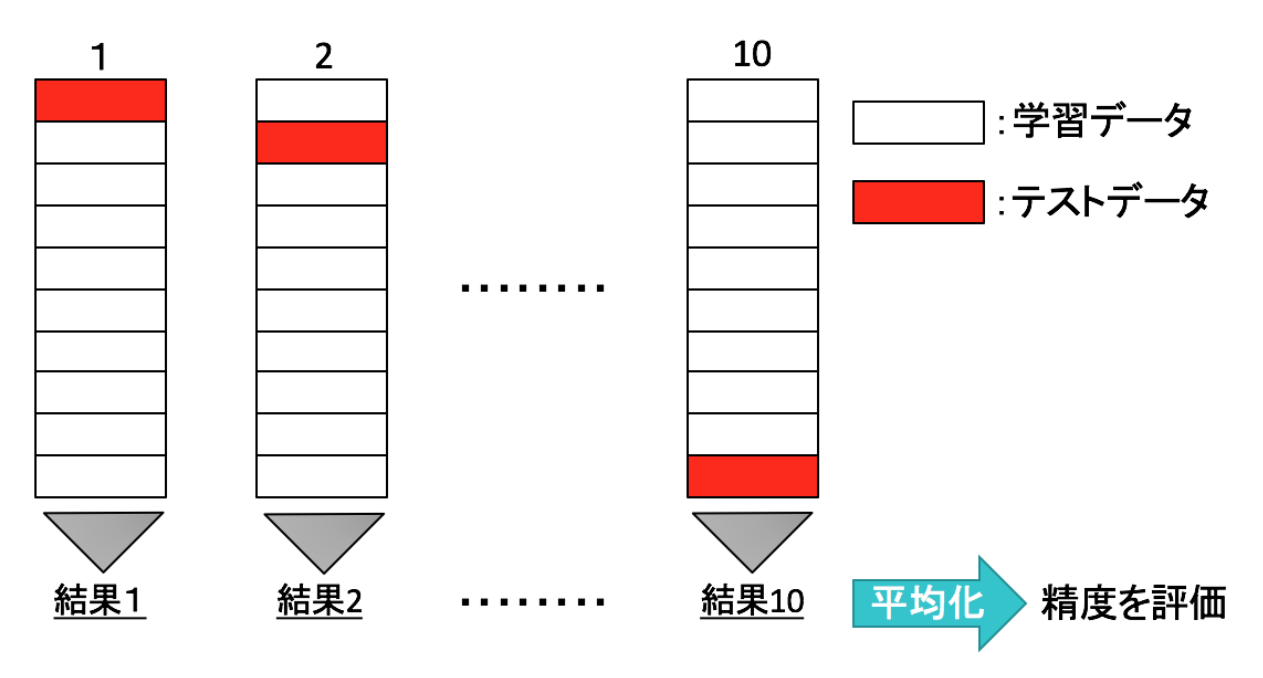
交差検証をするための関数は以下のようになります。
from sklearn.model_selection import cross_val_score, KFold
from scipy.stats import sem
def evaluate_cross_validation(clf, x, y, K):
cv = KFold(len(y), K,shuffle=True,random_state=0)
scores = cross_val_score(clf,x,y,cv=cv)
print(scores)
print ("Mean score: {} (+/-{})".format( np.mean (scores), sem(scores)))
引数1番目のclfは機械学習モデル(決定木、SVMなど)です。
引数最後のKはデータを何分割するか指定する引数です。
【無料動画:倍速で学ぶ!生成AIを活用したプログラミング勉強法(短縮版)】
生成AIを活用して効率的にプログラミングを学ぶ方法を解説しています。生成AIの基本的な仕組みや効果的な活用法、注意点についても詳しく説明。勉強法とともに生成AIそのものについても学べる内容となっています。ぜひご覧ください!
全編は、AI Academy公式LINEで配信中です。

グリッドサーチ
交差検証はモデルの汎化性能を測定する方法でした。
それに対してグリッドサーチは、学習モデルに用いられるハイパーパラメータを調整していき、モデルの汎化性能を向上させる方法を探す代表的な手法です。
グリッドサーチでは、指定したハイパーパラメータの全ての組み合わせに対して学習を行い、もっとも良い精度を示したパラメータを採用していきます。
ハイパーパラメータとは、SVCでのカーネルのバンド幅gamma、正則化パラメータCなどのことで人が調整する必要のあるパラメータのことをハイパーパラメータと呼びます。
グリッドサーチでハイパーパラメータを最適化
このパラメータはモデルの性能に大きく影響を与えます。
例えば、ハイパーパラメータであるgammaとCにそれぞれ0.001, 0.005, 0.1, 1, 5などと当てはめて、モデルの汎化性能を試してみるだけで、5×5=25通りのハイパーパラメータの組み合わせがありますが、それら全ての中で汎化性能の一番良いものを採択します。
グリッドサーチはScikit-learnを用いて実装できます。
# from sklearn.grid_search import GridSearchCV
from sklearn.model_selection import GridSearchCV
次に、最適化したいモデルのハイパーパラメータの設定を行いましょう。
例えば、 SVMにおいて、Cとgammaをそれぞれ{1,5,10,50},{0.001,0.0001}で最適化したいとすると、このようにリスト内に、keyにCとgammaを持つ辞書を入れれば良いです。
parameters = [
{'C': [1, 5, 10, 50],
'gamma': [0.001, 0.0001]}
]
グリッドサーチを使ったモデルを作成します。
from sklearn import svm
svc = svm.SVC()
clf = GridSearchCV(svc, parameters)
clf.fit(X_train, y_train)
結果はclf.best_params_で最適化したパラメータを確認できます
print(clf.best_params_)
評価まとめ
以上の評価指標をまとめて出力させる関数を作っておくと非常に便利です。
from sklearn import metrics
def measure_performance(x,y,clf, show_accuracy=True,show_classification_report=True, show_confussion_matrix=True):
y_pred=clf.predict(x)
if show_accuracy:
print("Accuracy:{0:.3f}".format(metrics.accuracy_score(y, y_pred)), "\n")
if show_classification_report:
print("Classification report")
print(metrics.classification_report(y, y_pred), "\n")
if show_confussion_matrix:
print("Confussion matrix")
print(metrics.confusion_matrix(y, y_pred),"\n")
if show_accuracy:
if show_classification_report:
if show_confussion_matrix:
ですが条件文にしている理由は、その関数がパフォーマンスの非表示をするためのものだからです。
関数はデフォルト引数で全てTrueを取っているため、そのまま呼び出すと全ての評価指標について出力しますが、例えばaccuracyだけ欲しい時などがあります。
そこでそれ以外をFalseに指定して, その関数を使うということがあります。
まとめ
このテキストでは、分類でも回帰でも利用可能な交差検証について学びました。
他にもホールドアウト法やグリッドサーチもよく利用しますので、しっかりと使えるようになりましょう。
✨AI人材コース 受講お申込み受付中!
AI Academy Bootcamp ではAI・データサイエンス、機械学習、Webアプリ開発の実践力を高める全6コース約50時間以上の動画が見放題!AIの学習に必須のPythonの学習から始まり、ITリテラシー、LLM学習など、目的に応じた幅広い分野をカバーしています。LINE公式では、お得な割引クーポンもプレゼントしています!
単独で学ぶより、全コースを一気に学ぶことで得られる「学習シナジー効果」が特長。
基礎から応用まで、データ分析とAI開発のスキルを効率よく身につけられます。





[…] オススメ記事 […]