

AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取るはじめに
この章では、簡単にロジスティック回帰の説明と、Scikit-learnで扱うための方法を学びます。
詳しい理論に関しては、機械学習アルゴリズム(理論編)のパーセプトロンとロジスティック回帰を参考にして見てください。
ロジスティック回帰
ロジスティック回帰(logistice regression)は出力変数が1もしくは0の2値になる2値分類を予測する手法です。
具体的には任意の値を0から1に置き換えるシグモイド関数を用いて、与えられたデータから2つに分けます。
ロジスティック回帰は、線形分類問題と二値分類問題に対する分類モデルで、2つのグループに分けたい問題(線形分離可能な問題)にロジスティック回帰を活用できます。
(ロジスティック回帰の名前には「回帰」とついておりますが、分類のためのアルゴリズムですので、回帰と混同しないようにしましょう。)
ロジスティック回帰の活用例
ロジスティック回帰は判定確率を求めることが出来るため、分類の確信度合いを0~1の確率で算出出来ます。
このような特徴からダイレクトマーケティング、医療分野等で利用されます。
・患者が癌か癌ではないかの判定
・届いたメールがスパムメールか、通常メールか(メールのスパムフィルタ)
・月額課金サービスのユーザーが解約するかしないかを判定
・クレジットカードの取引不正検知
・ダイレクトマーケティングを送り、反応するかしないか
・ある顧客が商品を買うか買わないか
・ある顧客が何パーセントの確率で商品を買うか
分析イメージ
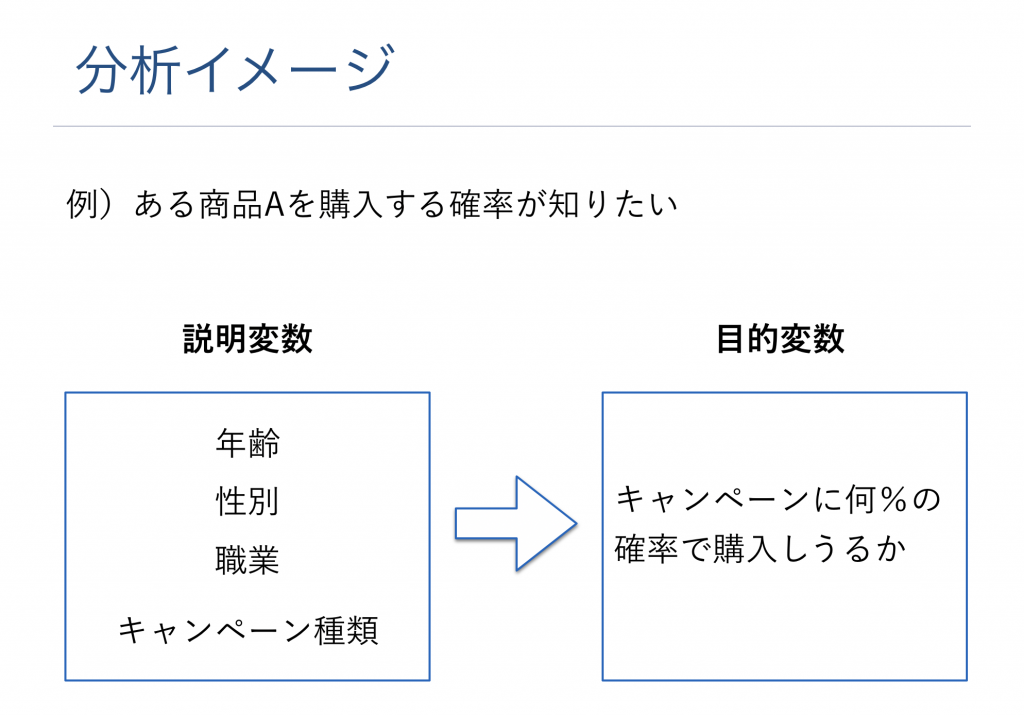
実装
ロジスティック回帰を実装するには、Sckit-learnのLogisticRegressionを使うことでモデルの実装が可能です。
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
dataset = load_iris()
X, y = dataset.data, dataset.target
# 分割 (トレーニングとテスト用にデータを分ける)して、モデルを作り、最後 に予測の精度を見ます
X_train, X_test, Y_train, Y_test = train_test_split(X, y)
# モデルの作成(初期化)
"""
Pythonのバージョンが3.7の場合、下記のコードだとWarningがでる場合があります。
その際には、model = LogisticRegression()の部分を、
model = LogisticRegression(solver='liblinear')
に書き換えてみてください。
"""
# モデル作成(初期化)
model = LogisticRegression()
model.fit(X_train, Y_train)
# 値の予測
pred = model.predict(X_test)
# テストデータを使って、どれくらい正しいかどうかを計算
accuracy_score(Y_test, pred)
上記を実行すると、正解率が90~97%あたりになります。
まとめ
この章では、ロジスティック回帰に関して学んできました。
ロジスティック回帰は、2値分類に利用できるアルゴリズムでした。
線形分離可能な場合に有効な手法ですので、是非使えるようにしましょう。
ロジスティック関数やオッズ、オッズ比、対数オッズなどに関して
この記事ではロジスティック関数やオッズ、オッズ比、対数オッズ、ロジスティック回帰の実装をscikit-learnなどのライブラリを用いて0から実装に関する話題に関しては解説していません。それらの内容まで学びたい方は、AI Academy Bootcampを検討してみてください。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!

