

Webスクレイピングとは
Webスクレイピング(Scraping)とは、Webサイトから任意の情報を抽出、整形、解析する技術のことです。
Pythonにはスクレイピングをするためのライブラリがいくつかありますが、ここでは「BeautifulSoup」(ビューティフル・スープ)を使って、スクレイピングします。
Beautiful Soupを使うことで、手軽にHTMLやXMLから情報の抽出が可能です。Beautiful SoupはHTMLなどの解析するためのライブラリですので、データのダウンロードを行う場合は、urllibもしくはrequestsなどを使います。
このサイトは、Pythonや生成AIなどを学べるオンラインプログラミングスクール AI Academy Bootcampが運営しています。
AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取るWebスクレイピングの活用事例
Webスクレイピングの活用事例として大きく3つあげられます。
1. マーケティング
2. 業務効率化
3. サービス開発
まずマーケティングですが、Webスクレイピングを活用することで、毎日定期的に確認する株価の変動やニュースメディアからの最新記事などの情報を自動で収集することができます。
次に、業務効率化を実現可能です。例えば、Twitterの特定の検索条件のツイートを数百件自動収集したりすることが出来ます。もちろん、手動でツイートを集めることも出来ますがかなりの労力がかかってしまいます。
最後に、スクレイピングを利用したWebやアプリケーション開発が可能となります。Googleのような検索エンジンや定期的に収集したデータをサービス開発に役立てることも可能です。
Webスクレイピングを実施する上での注意事項
クレイピングを行う前に、確認するべき点や、作業中に気を付ける必要がある点がいくつかかありますので説明します。
1)APIが存在するかどうか APIを提供しているサービスがあればそちらを使い、データを取得しましょう。それでも、十分なデータが得られない等の問題があるのであればスクレイピングを検討します。
2)取得後のデータの用途に関して取得後のデータを使う場合には、注意が必要です。取得先のデータは自分以外の著作物にあたり、著作権法に抵触しないように考慮する必要があるためです。
私的利用のための複製(第30条)情報解析のための複製等(第47条の7)※2019年1月1日の改正著作権法により、この47条の7が廃止され、新しい条文である新30条の4や新47条の5が発効します。
詳しくは下記記事をご確認ください。
進化する機械学習パラダイス ~改正著作権法が日本のAI開発をさらに加速する~
複製権
1) 複製権複製権は、著作権に含まれる権利のひとつで、著作権法第21条で規定されています。
(第21条「著作者は、その著作物を複製する権利を専有する。」)
複製とは、作品を複写したり、録画・録音したり、印刷や写真にしたり、模写(書き写し)したりすること、そしてスキャナーなどにより電子的に読み取ること、また保管することなどを言います。
引用元: https://www.jrrc.or.jp/guide/outline.html
翻案権
2) 翻案権翻訳権・翻案権は、著作権法第二十七条に規定されている著作財産権です。第二十七条では「著作者は、その著作物を翻訳し、編曲し、若しくは変形し、又は脚色し、映画化し、その他翻案する権利を専有する」(『社団法人著作権情報センター』より)と明記されています。反対に見ると、これらを著作者の許諾なしに行うと、著作権の侵害になるということです。引用元: http://www.iprchitekizaisan.com/chosakuken/zaisan/honyaku_honan.html
公衆送信権
3) 公衆送信権公衆送信権は、著作権法第二十三条において規定される著作財産権です。この第二十三条では「著作者は、その著作物について、公衆送信(自動公衆送信の場合にあっては、送信可能化を含む。)を行う権利を占有する。」「著作者は、公衆送信されるその著作物を受信装置を用いて公に伝達する権利を占有する。」と明記されています。
引用元: http://www.iprchitekizaisan.com/chosakuken/zaisan/kousyusoushin.html
また上記を注意しながら、実際にスクレイピングを行う際に、書いたコードによってサーバに負荷がかからないようにしましょう。過度なアクセスはサーバに負担をかけてしまい攻撃だとみなされてしまい、最悪の場合一定期間サービスを利用できなくなってしまう可能性があります。
さらには、システムにアクセス障害が発生し、利用者の一人が逮捕された事件もありますので、常識の範囲内での使用してください。
岡崎市立中央図書館事件以上を踏まえた上で、次に進んでいきましょう。今回ターゲットとするWebサイトは、こちら側が用意したサーバーのWebサイトからスクレイピングして行きます。
Webスクレイピングの基本的な手順
大きく分けると3つ手順を行う必要があります。
1.Webページを取得する
2.スクレイピングする
3.抽出したデータを保存する
この3つの手順を行うことで、データを収集することが可能になります。
Webスクレイピングをする上で必要なライブラリ
Pythonをベースに説明します。
・「urllib」もしくは「Requests」 HTTPライブラリ
・BeautifulSoup HTMLの構造を解析するライブラリ(Webスクレイピング用のライブラリ)
・Scrapy Webスクレイピングフレームワーク
場合によっては、PhantomJSもしくはSeleniumを使うこともあります。
HTMLとCSS
スクレイピングをするにあたって、HTMLとCSSに関しての基本を知っておくと便利です。
HTMLとはHyperText Markup Languageの略で、Webページを作成するためのマーク アップ言語の1つです。CSS(Cascading Style Sheets)とは、HTML文書の装飾やレイアウトをつくるための言語です。
Webページは「文章の構造を定義するHTML」と「デザインを指定するCSS」のセット」で作られています。
Webサイトからデータを取得しよう
スクレイピングの基本的な手順の1つ目にあたる『1.Webページを取得する』を実施しましょう。
Pythonを使いWebサイトからデータを取得する方法を紹介します。ここでは、Pythonに標準で用意されている「urllib」というライブラリを使います。
urllibは、URLを扱うモジュールを集めたライブラリです。Pythonのurllibを使うことで、画像の取得や、HTMLデータの取得ができます。urllib.requestモジュールにあるurlretrieve()関数を使うことで、直接ファイルを取得できます。下記のコードからAI Academyのサーバにあるロゴ画像を保存してみましょう。
import urllib.request
imgname = "logo_courses_ai.png"
url = "https://aiacademy.jp/assets/images/" + imgname
# urlretrieveの第一引数はアップロードされている画像のURL、第二引数には保存したい画像ファイル名
urllib.request.urlretrieve(url, imgname)
print("保存完了")出力結果
保存完了上記のプログラムを実行すると「logo_courses_ai.png」というファイル名で上記のプログラムを実行したパス(ファイルやフォルダの場所)に保存されています。
以下のような画像(「logo_courses_ai.png」)が保存されているか確認してみてください。
Requests を用いる場合
Pythonには他にも先ほど紹介したHTTPライブラリのurllib以外にもRequestsというライブラリもあります。
# GETリクエスト
import requests
res = requests.get("https://aiacademy.jp")
print(res) # <Response [200]>
print(res.text) # 帰って来たレスポンスボディをテキスト形式で取得【無料動画:倍速で学ぶ!生成AIを活用したプログラミング勉強法(短縮版)】
生成AIを活用して効率的にプログラミングを学ぶ方法を解説しています。生成AIの基本的な仕組みや効果的な活用法、注意点についても詳しく説明。勉強法とともに生成AIそのものについても学べる内容となっています。ぜひご覧ください!
全編は、AI Academy公式LINEで配信中です。

BeautifulSoupでスクレイピングする
Beautiful Soupはインストールは下記コマンドでインストール可能です。
pip install bs4上記のインストールコマンドはMacの方はターミナル、Windowsの方はコマンドプロンプトで実行します。
さて、まずはfind()メソッドから見ていきましょう。
find()メソッド
find()メソッドを利用することで、任意のid属性を指定し要素を見つけることが出来ます。
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://aiacademy.jp/assets/scraping/sample1.html")
data = html.read()
html = data.decode('utf-8')
# HTMLを解析
soup = BeautifulSoup(html, 'html.parser')
# 解析したHTMLから任意の部分のみを抽出(ここではtitleとbody)
title = soup.find("title")
body = soup.find("body")
print("title: " + title.text)
print("body: " + body.text)出力結果
title: AI Academy(エーアイ アカデミー)
body:
AI Academyとは?(エーアイ アカデミーとは?)
人工知能プログラミングに特化したマンツーマン オンラインプログラミングスクールです。
プログラミング言語Pythonを使いながら、機械学習や深層学習などを学習します。findメソッドの引数attrsに属性を指定することが出来ます。attrsは辞書で指定します。例えばクラス名を指定して取得するには以下のように記述可能です。
import requests
from bs4 import BeautifulSoup
url = "https://www.nikkei.com/markets/kabu/"
# 株価の取得
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
price = soup.find("span", attrs={'class':'mkc-stock_prices'})
print(price.text)attrsのclassの部分をidにする事で、ID名を指定して取得する事も出来ますので知っておくとidにも対応可能です。またクラス名の場合に、class_という別名で以下のように書き換える事も出来ます。
import requests
from bs4 import BeautifulSoup
url = "https://www.nikkei.com/markets/kabu/"
# 株価の取得
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
price = soup.find("span", class_='mkc-stock_prices')
print(price.text)さらにfindメソッドの引数にtextオプションを用いる事で、指定したタグ内に【2020年版】という文字が含まれるタグtitleを取得したい場合は正規表現と組み合わせて以下のように書けます。
import requests
from bs4 import BeautifulSoup
import re
url = "https://aiacademy.jp/media/?p=455"
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
#print(soup)
text = soup.find("title", text=re.compile('【2020年版】*'))
print(text)出力結果
<title>【2020年版・初心者向け】独学でAIエンジニアになりたい人向けのオススメの勉強方法 | AI Academy Media</title>find_all()メソッド
find_all()を使うと、複数の要素(タグ)を一気に取得することが出来ます。
また、find_all()にはキーワード引数を指定することが可能です。
キーワード引数にidに値を渡すとタグの’id’属性に対して取得可能です。soup.find_all(id='ID名')また以下のコードでは、特定のタグにクラス名を指定して取得できます。
soup.find_all('タグ', class_="クラス名")
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://aiacademy.jp/assets/scraping/sample2.html")
data = html.read()
html = data.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all("a")
for a in links:
href = a.attrs['href']
text = a.text
print(text, href)出力結果
AI Academy1 http://aiacademy.jp
AI Academy2 http://aiacademy.jp
AI Academy3 http://aiacademy.jpテキストの取得
テキストの取得には.titleもしくはget_text()を用いる事で、テキストを取得する事が出来ます。
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://aiacademy.jp/assets/scraping/sample1.html")
data = html.read()
html = data.decode('utf-8')
# HTMLを解析
soup = BeautifulSoup(html, 'html.parser')
# 解析したHTMLから任意の部分のみを抽出(ここではtitleとbody)
title = soup.find("title")
body = soup.find("body")
print("title: " + title.text)
print("body: " + body.text)
title2 = soup.find("title").get_text()
body2 = soup.find("body").get_text()
print("title2: " + title2)
print("body2: " + body2)記述量は多いですが、get_text()は関数のため、便利な引数が用意されています。
例えば上記のbodyとbody2はそれぞれ.titleとget_text()を用いて取得していますが、どちらも改行やスペースが入った場合に限り同じ出力になっています。このような場合、get_text()の引数にstripオプションをTrueにする事で、改行や空白文字を除去する事が出来て便利です。
body3 = soup.find("body").get_text(strip=True)
print("body3: " + body3)改行や空白文字を除去する必要がなく、ただ単にテキストだけを取得したい場合には.textを用い、テキストの取得と同時に改行や空白文字を除去したい場合にはget_text()を利用するといった具合に使い分けすると良いです。
CSSセレクタ
CSSセレクタの説明に入る前に少し、「CSS」と「セレクタ」に関して説明します。まず、CSSの基本的な書き方は次の通りです。
セレクタ {
プロパティ:値;
}セレクタとは一言でいうと、スタイルを適用する対象のことです。セレクタには、「HTMLの要素」、「class名(プログラミングのクラスではありません)」、「ID名」の3つがセレクタの基本セレクタです。他にもセレクタの種類はいくつかあります。
CSSセレクタスクレイピングをする際に、CSSのセレクタを指定して、任意の要素を抽出することが出来ます。
# これは記述例ですので、このままだと動きません。
soup.select_one(セレタク) CSSセレクタで要素を1つ取り出す
soup.select(セレクタ) CSSセレクタで複数要素を取り出しリスト型で返す次のプログラムはCSSセレクタを使ったサンプルプログラムです。
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://aiacademy.jp/assets/scraping/sample3.html")
data = html.read()
html = data.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
h1 = soup.select_one("div#main > h1").string
print("h1: ",h1)
li_list = soup.select("div#main > ul.items > li")
for li in li_list:
print("li: ", li.string)スクレイピングのためのChrome開発者ツール入門
スクレイピングを行うには、HTMLの構造解析が必要になります。そこで、今回は、Google Chromeの開発者ツールを使います。まず対象のサイト(AI Academy Media)へアクセスします。 そこで一番下にある『検証』を押します。検証を押すと次のような画面が表示されます。
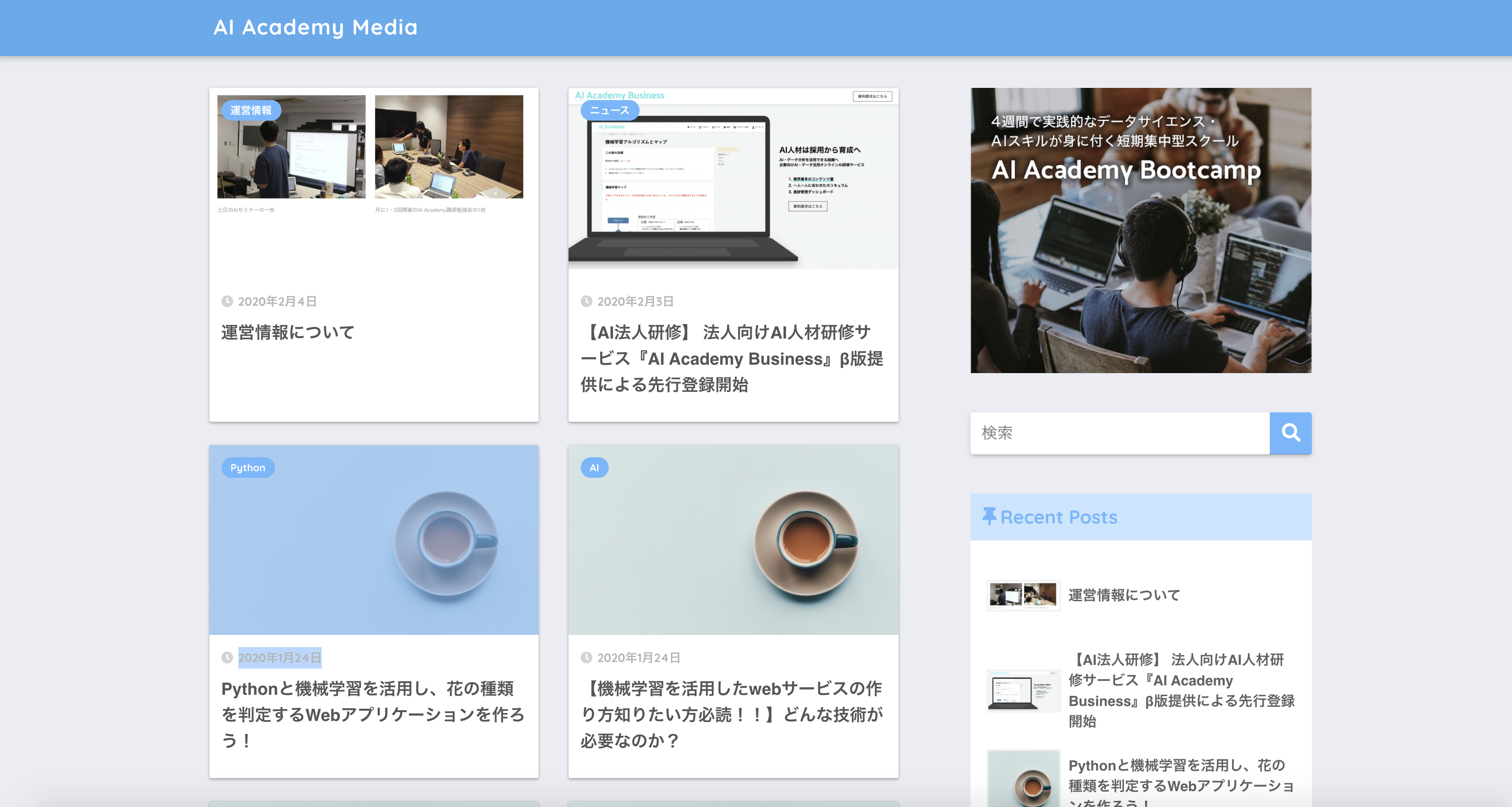
アクセスしたら、右クリックを押します。以下のようなポップアップが表示されます。
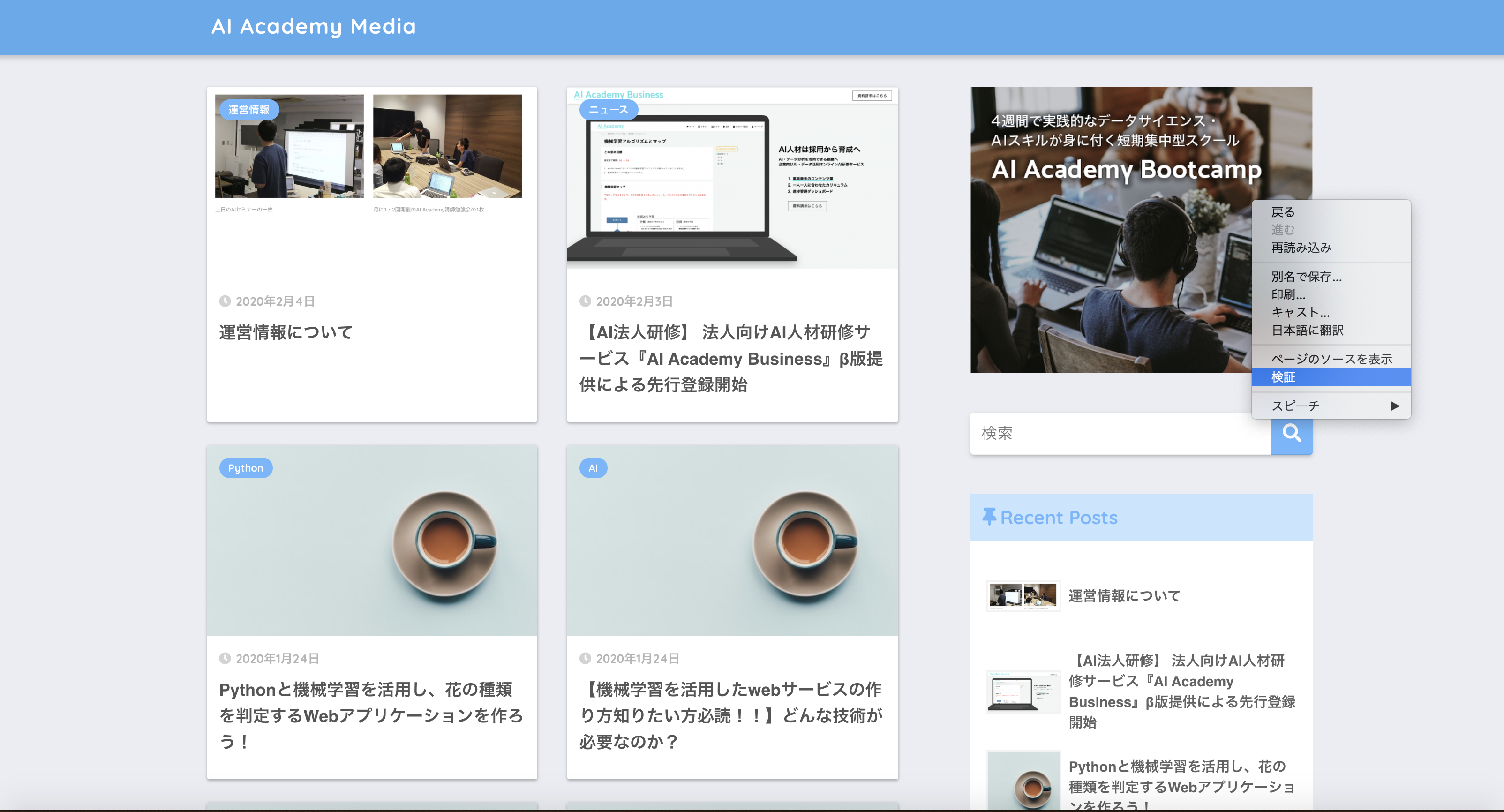
ポップアップの検証をクリックします。クリックすると以下のような画面が表示されます。
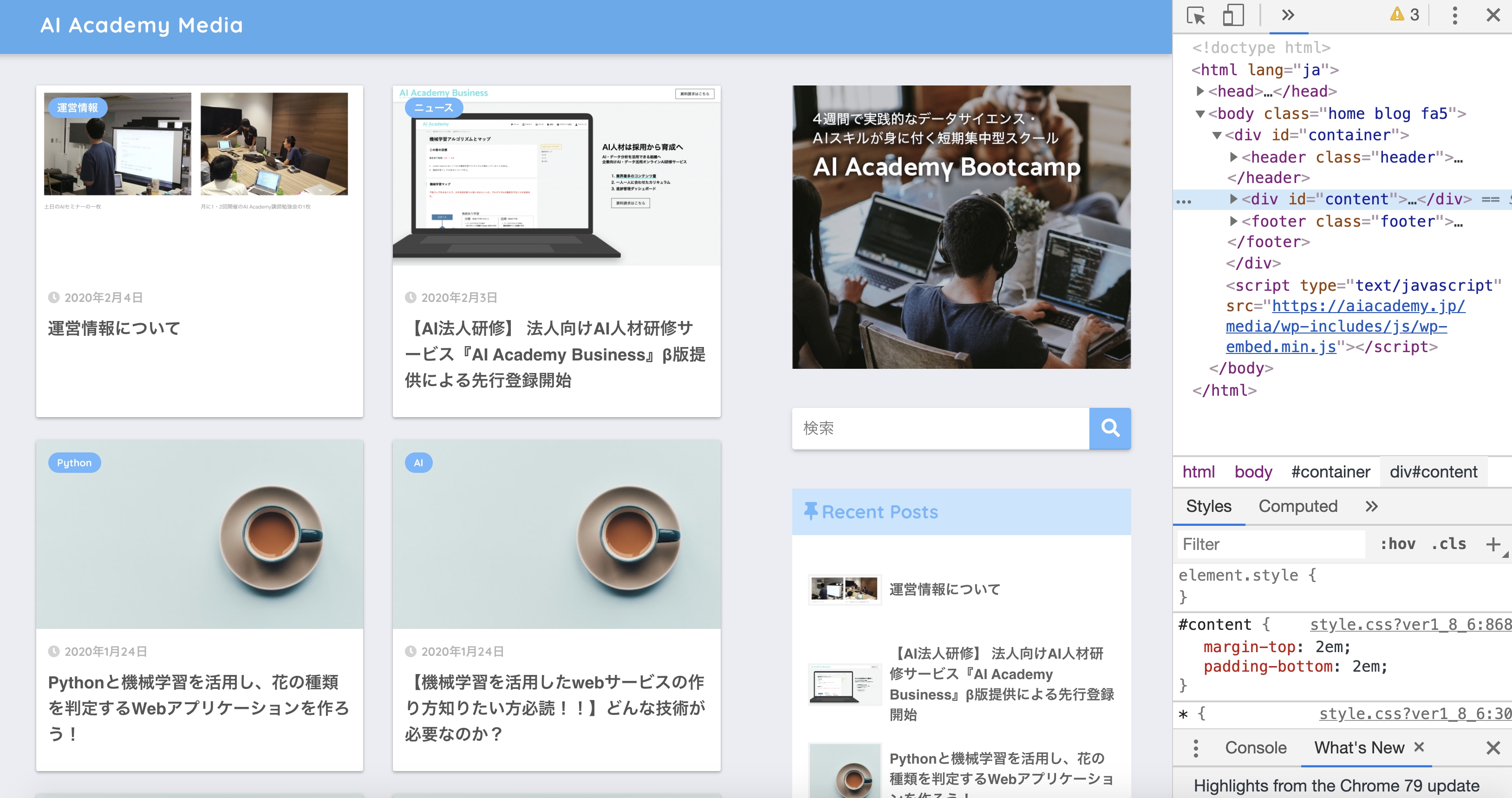
ちなみに、検証ツール(デベロッパーツール)はキーボードのショートカットキーからでも起動することが出来ます。Mac OSの方は、Commnd+option+iを同時に押します。(Windowsの方は、Ctl+Alt+iキーを同時に押します。)便利ですので、是非覚えておきましょう。
cssセレクタでスクレイピング実践
では、AI Academy Mediaにアクセスし、『AI Academy Media』という文字を、cssセレクタでスクレイピングして見ましょう。
from bs4 import BeautifulSoup
from urllib.request import urlopen
target_url = "https://aiacademy.jp/media"
html = urlopen(target_url)
data = html.read()
html = data.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
data = soup.select("#logo > a")
print(data[0].text)次の6つのSTEPでCSSセレクタを取得可能です。
1. STEP1 開発者ツールで検証を開く。
2. STEP2 開発者ツール矢印ボタンを押して青色にする。
3. STEP3 青色にしたら、取得したい部分を選択しクリックする。
4. STEP4 青色ラインが引かれるので、左の白の・・・を選択する。
5. STEP5 copy > Copy selectorを押すとクリップボードにコピーされる。
6. STEP6 貼り付けする。
それでは順番に見ていきましょう。
1. STEP1 開発者ツールで検証を開く。2. STEP2 開発者ツール矢印ボタンを押して青色にする。
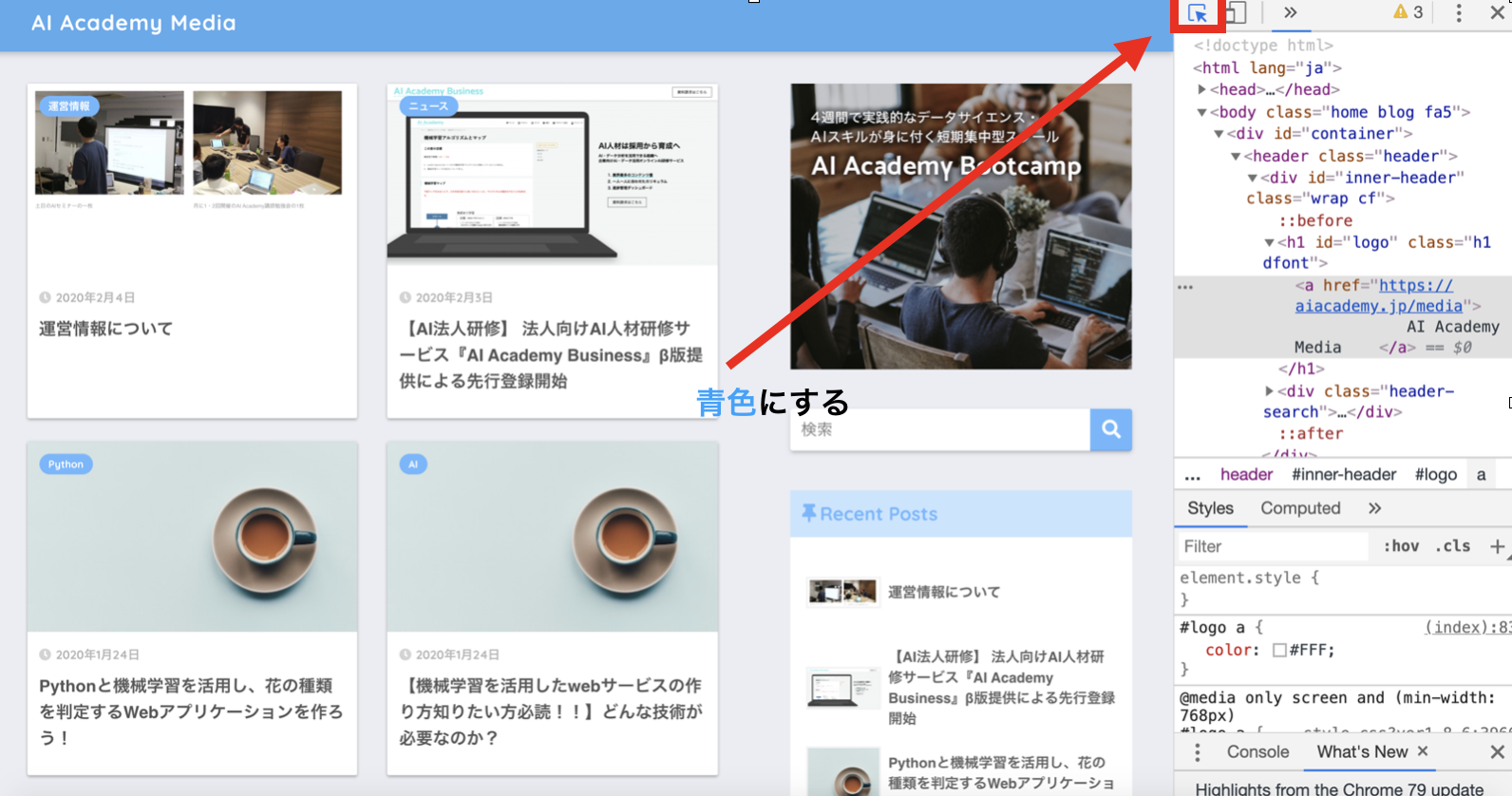
3. STEP3 青色にしたら、取得したい部分を選択しクリックする。(今回は下記画像の左上の『AI Academy Media』という文字をスクレイピング(抽出)します。)
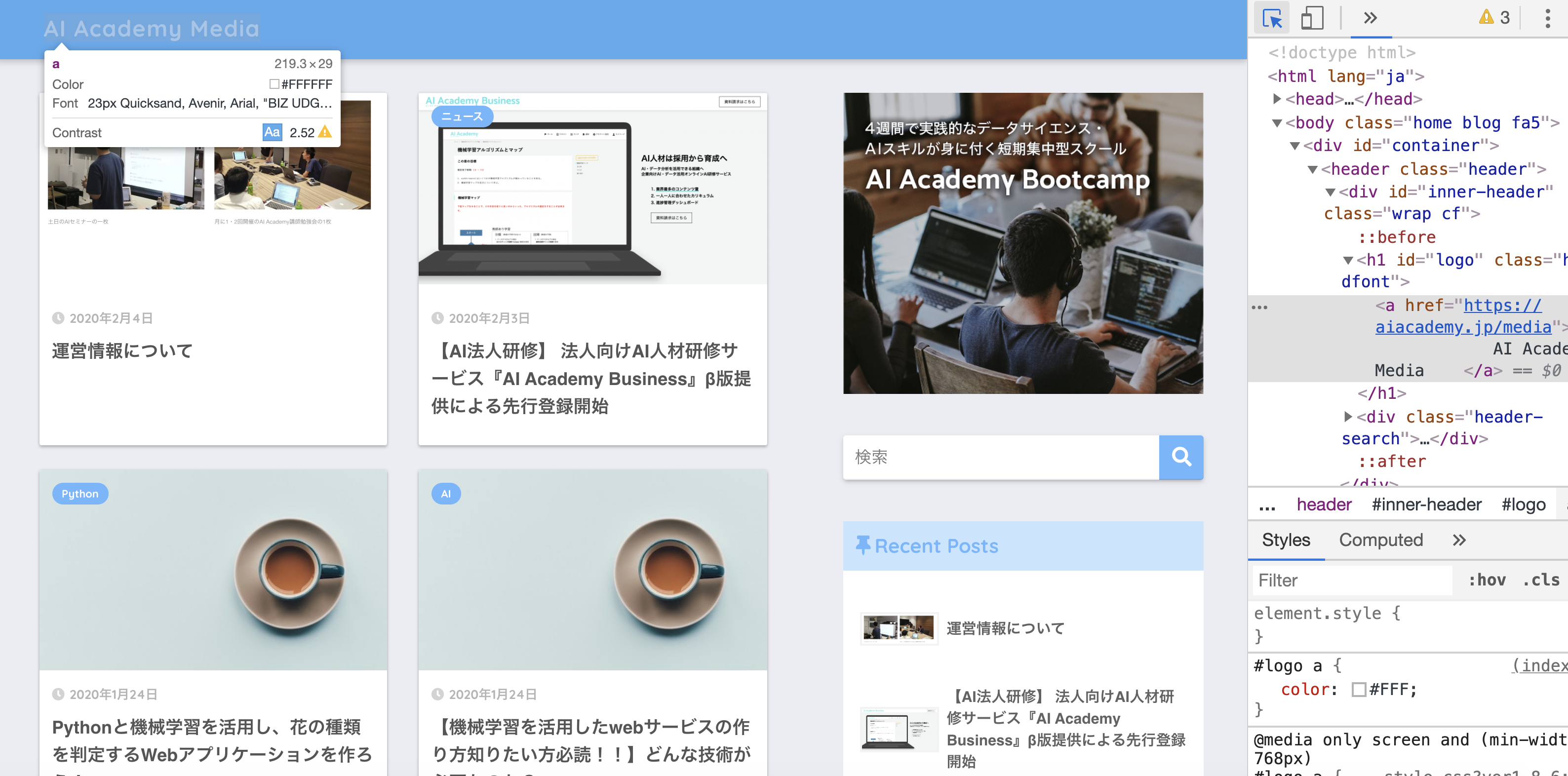
4. STEP4 青色ラインが引かれるので、左側にある『・・・』アイコンをクリック(選択)します。
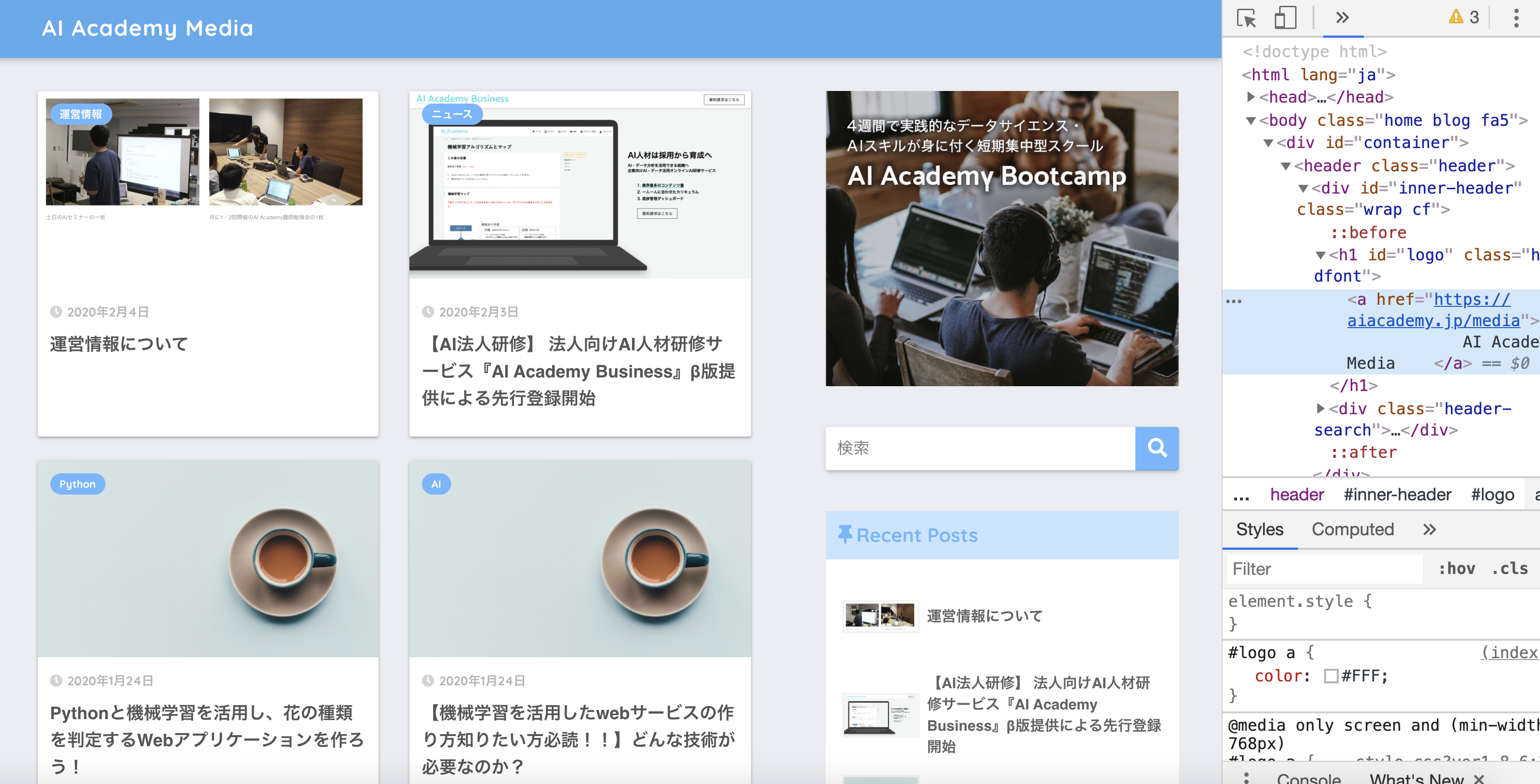
5. STEP5 『・・・』を押すと、copy > Copy selectorと書かれたポップアップが表示されますので、Copy▶︎Copy Selectorを押すとCSSセレクターがクリップボードにコピーされます。
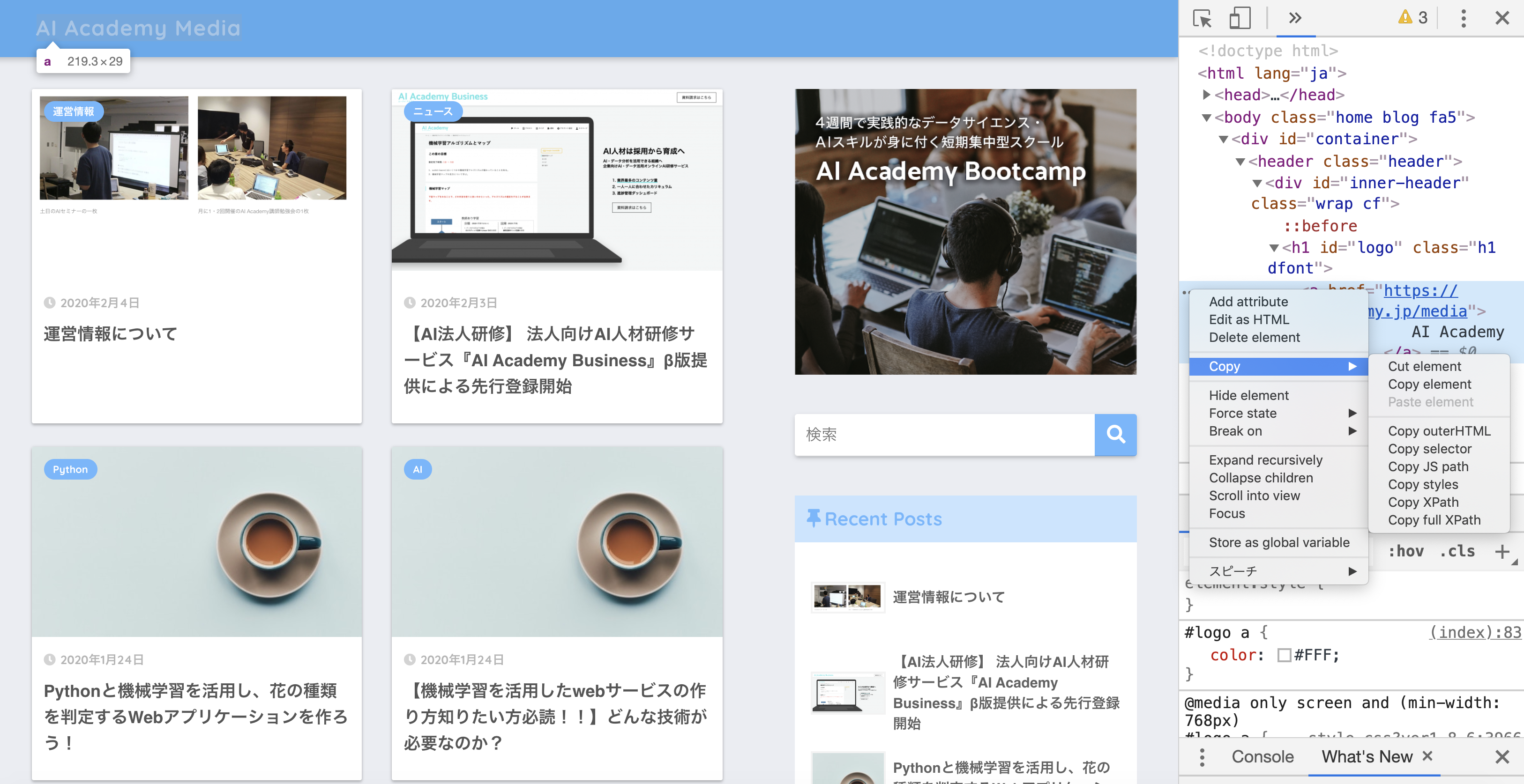
6. STEP6 Jupyter Notebookのセルや使用しているテキストエディタに貼り付けする。 貼り付けすると次のようなコードが貼り付けられます。#logo > aこれがcssセレクターです。
CSSセレクタに関して補足
cssセレクタをコピーした際に、nth-child(2)といったような書式が出てくる場合があります。
その場合、BeautifulSoupはnth-childの記述方法に対応していないため、nth-of-typeを使う必要があります。
nth-child(n)というのは、n番目の子となる要素を意味しております。
nth-of-type(n)はn番目のその種類の要素という意味でこちらを使えば取得可能です。
セレクタをそのままとってもうまくとれない場合がありますが、セレクタを多少修正する必要があるとはいえ、目視でセレクタを取得するよりChromeの検証ツールを使うことで簡単に必要なセレクタを取得できます。
(実際に検証ツールでそのまま取得したセレクタだとデータが取得できない場合はよくありますので、その都度取得したセレクタを調整したりします。)
おわりに
この記事では、Webスクレイピングとは何かを解説し、Pythonを用いてWebスクレイピングを行う方法を学びました。この記事で学んだことを活かしてWebスクレイピングを活用してみてください。
関連:Pythonで画像データをスクレイピング 手軽に画像収集したい方必読!
Pythonやデータ分析を効率よく学ぶには?
✨AI人材コース 受講お申込み受付中!
AI Academy Bootcamp ではAI・データサイエンス、機械学習、Webアプリ開発の実践力を高める全6コース約50時間以上の動画が見放題!AIの学習に必須のPythonの学習から始まり、ITリテラシー、LLM学習など、目的に応じた幅広い分野をカバーしています。LINE公式では、お得な割引クーポンもプレゼントしています!
単独で学ぶより、全コースを一気に学ぶことで得られる「学習シナジー効果」が特長。
基礎から応用まで、データ分析とAI開発のスキルを効率よく身につけられます。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!


[…] 関連:PythonでWebスクレイピングしてみよう! […]