

AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取るMLflow とは
MLflowとは、機械学習の開発を行う上で複雑になりがちな実行環境、モデル、パラメータ、評価指標などの実験管理を行ってくれるプラットフォームです。
(実験管理とは、機械学習のモデルの開発・運用におけるアルゴリズム、ハイパーパラメター、評価指標を記録し、後から再現できるように整理すること)
現在、MLflowは以下の4つのコンポーネントを提供しています。(この記事では1つ目のMLFlow Trackingに関して解説します。)
MLflowの4つのコンポーネント
MLFlow Tracking
MLFlow Trackingでは、実験管理(コード、データ、設定、結果)が簡単にできます。
MLflow Projects
MLflow Projectsでは、データサイエンス・コードをパッケージ化し、あらゆるプラットフォームでの実行を再現できます。
MLflow Models
MLflow Modelsでは、機械学習モデルを多様なサービス環境への展開できます。
Model Registry
Model Registryでは、リポジトリにモデルを保存等ができます。
MLflow インストール
MLflow(MLflow Tracking)を使うには、まずMLflowをpipコマンドでインストールします。
pip install mlflow今回の記事で解説するバージョンは、 ‘1.23.1’ とします。
import mlflow
print(mlflow.__version__) # 1.23.1MLFlow Tracking
MLflow racking API よりコードを引用し、実際に入門してみます。
引用した一部コードには日本語でコメントを補足しています。
下記のコードをmain.py などで保存し実行します。
# MLflow racking API よりコード部分引用
# https://www.mlflow.org/docs/latest/quickstart.html
import os
from random import random, randint
from mlflow import log_metric, log_param, log_artifacts
if __name__ == "__main__":
# パラメータ(キーと値のペア)を記録する
log_param("param1", randint(0, 100))
# 指標を記録し、実行中に指標を更新することが可能( MLflowに記録)
log_metric("foo", random())
log_metric("foo", random() + 1)
log_metric("foo", random() + 2)
# アーティファクト(出力ファイル)のログ
if not os.path.exists("outputs"):
os.makedirs("outputs")
with open("outputs/test.txt", "w") as f:
f.write("hello world!")
log_artifacts("outputs") # フォルダごと記録python main.py実行後、mlruns と outputsフォルダが生成されます。
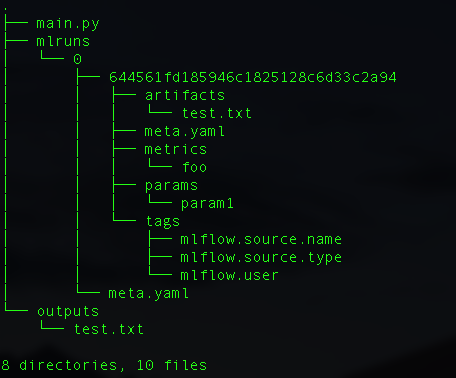
MLFlowでメトリックスやパラメータを管理したい場合には、それぞれ以下のメソッドを利用します。
メトリック log_metric
mlflow.log_metric("mse", 2500.00)パラメータ log_param
mlflow.log_param("learning_rate", 0.01)トラッキングUIを表示
その後、下記のコマンドを実行すると、http://127.0.0.1:5000 をWebブラウザからアクセスすると、ダッシュボードページが立ち上がります。
mlflow ui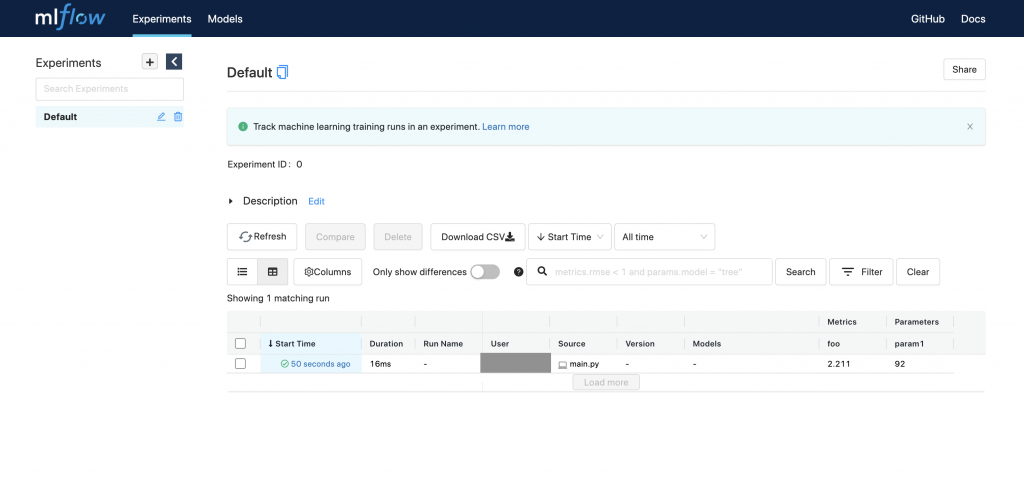
上記の画面より実験結果を管理することが出来ます。
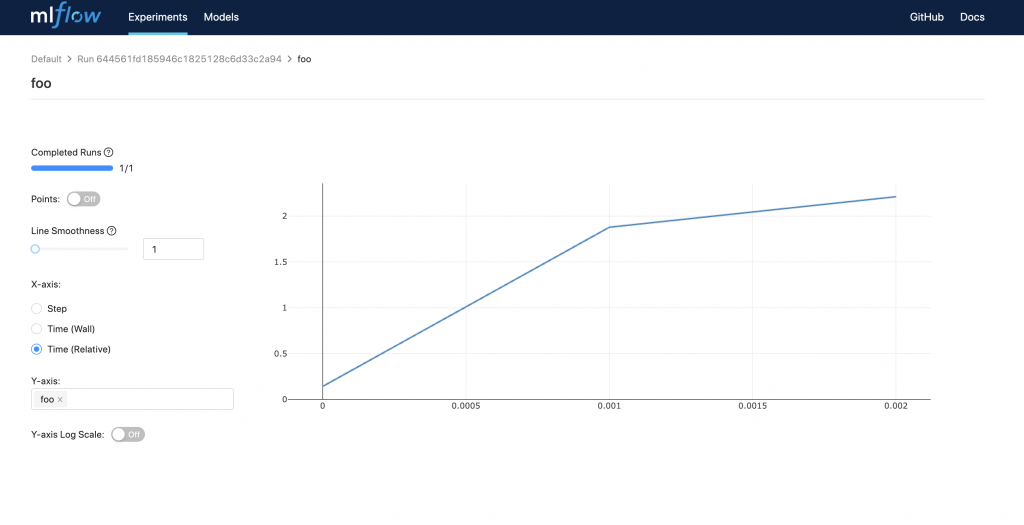
リモートトラッキングサーバーへログを記録する
リモートマシンでトラッキングサーバーを起動するには、環境変数MLFLOW_TRACKING_URIにサーバーのURIを設定するか、プログラムの先頭に以下を追加することで、リモートトラッキングサーバーにログオンすることができます。
import mlflow
mlflow.set_tracking_uri("https://・・・") # トラッキングサーバーを指定
mlflow.set_experiment("my_first_exp") # 実験を管理(指定しない場合、Defaultが設定)おわりに
この記事では、実験管理の課題を解決するためにMLFlow(MLflow Tracking)を紹介し、実際に入門してみました。
Kaggleなどで大量に実験をする場合に、モデルの管理を楽にしたい時がありますが、そのような場合にMLflow Trackingは大変有効なツールとなります。
以前作成したモデルなどを管理したい場合には是非利用してみてください。
参考記事
参考記事(MLflowの使い方 〜高レベルAPIでの簡単入門と低レベルAPIでの簡単入門〜)
ハイパラ管理のすすめ -ハイパーパラメータをHydra+MLflowで管理しよう-
機械学習を効率よく学ぶには?
機械学習を効率よく学ぶには、普段からPythonを利用している現役のデータサイエンティストや機械学習エンジニアに質問できる環境で学ぶことです。
質問し放題かつ、体系的に学べる動画コンテンツでデータ分析技術を学びたい方は、オンラインで好きな時間に勉強できるAI Academy Bootcampがオススメです。受講料も業界最安値の35,000円(6ヶ月間質問し放題+オリジナルの動画コンテンツ、テキストコンテンツの利用可能)なので、是非ご活用ください。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!

