

この記事ではPythonでデータ分析を入門してみたい方向けの記事になります。
本記事の流れとして、データ分析とは何か、データ分析の手順を学び、Pythonのデータ分析ライブラリであるPandasを用いてデータ分析を体験してみます。
データ分析の内容としましては、Pandasを用いて様々な基本統計量を算出します。
さらに、データの欠損値処理をしたり、相関分析なども学びます。
なお、本記事は文章量が多いため、気になった項目のみ読んでいただくか、読者の方のペースで少しずつ読み進めてみてください。またPythonのサンプルプログラムを多く載せていますので、なるべく手を動かして学んで頂けるとより力が付くかと思います。

AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取るデータ分析とは
データ分析とは「データ」を用いて「問題」を解決することです。
ビジネス現場においては、意思決定のためにデータ分析を行います。本来データ分析という言葉の意味合いは広い意味合いを持ちますが、「データ」から「問題」を解明するというプロセスになります。
問題を明確にしてからデータ分析を行う事が大事です。
闇雲にデータ分析を行っても、曖昧な結果にしかなりません。加えビジネスにおいては、誰の意思決定のためにも利用されない(現場で使われない)データ分析は意味がありません。
次の節では、データ分析の手順としてPPDACサイクルを紹介致します。
データ分析の手順(PPDAC)
データ分析をこれから行う上で、データ分析の手順を理解しましょう。
データ分析は以下の5つの手順で進めていきます。
①問題の把握(Problem)
②調査の計画(Plan)
③データの収集(Data)
④データの分析(Analysis)
⑤結論を考える(Conclusion)
これは「PPDACサイクル」と呼ばれる問題解決フレームワークです。
このフレームワークをデータ分析に当てはめると、各段階をProblem(問題の把握)、Plan(調査の計画)、Data(データの収集)、Analysis(データの分析)、Conclusion(結論)に分けて考える事が出来ます。
①問題の把握(Problem)
まずは問題を把握しましょう。
「何が問題で、なぜデータ分析をするのか」を明確にします。以下の2点をチェックしましょう。
1. 問題を明確にする
2. 仮説を立てる
②調査の計画(Plan)
課題設定の次は、それについて調査・分析を行う計画を立てます。どんなデータが必要で、どんな方法で集めれば良いかを考えます。以下の2点をチェックしましょう。
1. 必要なデータを想定する
2. データ収集計画を立てる
③データの収集(Data)
次に分析で使うデータを収集します。データにも自社内のデータ(内部データ)と自社以外のデータ(外部データ)に分けられます。自社内のデータであれば、担当部署、担当者から必要なデータをもらったり、必要に応じてデータベースに格納されているデータをSQL等で取得します。
自社外のデータであれば、ネットで公開されているオープンデータを利用したり、必要に応じてWebスクレイピング等でデータを収集します。以下の2点をチェックしましょう。
1. データを収集する
2. データに不足がないか確認する
④データの分析(Analysis)
ここでやっとデータ分析を行います。データ分析には、データを要約したり、データの傾向を確認し、次のアクションに繋がるようにする事が大切です。
⑤結論を考える(Conclusion)
最後に、分析した結果から結論を導きだします。その後、分析レポートを作成し、分析した結果から価値ある施策に繋がるアクションを提案します。人が実行できる結論を考える事が大切です。
ただ、1回のPPDDACサイクルで問題が解決するとは限らないため、何度もこのPPDACサイクルを行い問題を解決していきます。
PPDACサイクルを通じて、データ分析の手順をご紹介しましたが、データ分析のプロジェクトでよく用いられるデータ分析のプロセスモデルの1つである「CRISP-DM」に関しても解説します。
CRISP-DMとは
CRISP-DM(CRoss-Industry Standard Process for Data Mining)とは、データ分析プロジェクトのためのデータ分析プロセスモデルです。CRISP-DMに沿ってデータ分析を行うことで、効率よくデータ分析を行うことが出来ます。
CRISP-DMでは以下のようなプロセスでデータ解析が行われます。

プロセスに矢印が引かれ、円形のプロセスマップからもわかる通り、データ解析の分野では必要に応じて、処理を戻りやり直したり、繰り返すことが求められます。
CRISP-DMの6つのプロセス
CRISP-DMには、次の6つのプロセスがあります。
❶ビジネス課題の理解
❷データの理解
❸データの準備
❹モデル作成
❺評価
❻展開・共有
ビジネス課題の理解
まず始めにビジネス課題を理解するところから始まります。(Business Understainding)
データの理解
ビジネス課題の理解の次は、データの理解のフェーズです。
データの理解のフェーズでは、分析のもととなるデータについて理解します。
データを理解するためには、ただ手を動かせば良いわけでなく、担当者との密なコミュニケーションが必要になります。さらに、可視化を行うことでデータ理解につながります。
データの準備
データの理解ができたら、モデルを作成する前段階としてデータを準備・前処理します。
データ前処理は、全体の8割を占めると一般的に言われます。
どのように特徴量を作成するかによって、次のフェーズのモデルの精度を左右します。
さらには、ビジネス理解のフェーズに定めた分析目標を達成できるかどうかにもつながるため、作業には十分に時間を割く必要があります。
モデル作成
データの準備・前処理を終えることで、はじめてモデルの作成が行えます。
このフェーズでモデル(データに潜むルールやパターンの集まり)を作成します。
評価
モデル作成フェーズで得られた結果から、分析の目標とビジネス目的を達成できるか評価します。
次の『展開・共有』フェーズで実際にモデルを運用し、効果を確認することも必要です。
評価の結果、ビジネス目的を達成できなければ、ビジネス理解のフェーズに戻り、再度分析の目標と成功の判定基準を設定します。
展開・共有
ビジネス目的を達成できるモデルを得られたら、既存の業務フローへ展開、共有し既存システムに組み込みます。
このフェーズでは組み込んで終わりではなく、効果をモニタリングしフィードバックを行い、さらなる改善を繰り返します。
モデルは一度作って終わりではなく、継続的に価値を出し続けるために、最新の状態に保つ必要があります。
分析の価値が下がらないよう、モデルは日々更新します。
(更新頻度はビジネスの目的によって異なります。)
Pandasとは
Pandas(パンダス/パンダズ)はデータ解析を容易にする機能を提供するPythonのデータ解析ライブラリです。
Pandasの特徴には、データフレーム(DataFrame)などの独自のデータ構造が提供されており、様々な処理が可能です。特に、表形式のデータをSQLまたはRのように操作することが可能で、かつ高速で処理出来ます。最新情報に関しては 公式ドキュメントを参考してください。Pandasを使うことで下記のようなことが出来ます。
・CSVやExcel、RDBなどにデータを入出力できる
・データの前処理(NaN / Not a Number、欠損値)
・データの結合や部分的な取り出しやピボッド(pivot)処理
・データの集約及びグループ演算
・データに対しての統計処理
なぜPandasを学ぶのか
なぜPandasを学ぶのかについて説明します。機械学習エンジニアやデータサイエンティストがPythonでデータの前処理をする上で、Pandasは必須と言って良いほど利用します。機械学習においてデータの前処理は多くの時間を割くことになりますが、Pandasを使うことでこのデータの前処理という工程を効率よく行うことが出来ます。
Pandasを使うメリット
Pandasを使うメリットは主に2つあります。
1. 多種の型のデータを一つのデータフレームで扱えることNumPyの配列(np.array)はすべての要素が同じ型でなければなりません。よって、csvファイルの読み書きなどでは、NumPyは不便だったりします。その点、Pandasのデータフレームは異なる型のデータを入れることが出来ます。Pandasのデータフレームに格納することで、データの前処理が容易にできます。
2.データ加工や解析の関数が多い
別章で示した欠損値の削除・補間の他にも、これから紹介する様々な便利な関数がPandasには備わっています。
Pandasを使う
Pandasを利用するには、Pandasのライブラリを読み込みする必要があります。以下のコードで、Pandasをpdという名前で扱えるようにしています。
import pandas as pdpipコマンドを用いたPandasのインストールは下記のコマンドでインストール出来ます。Macの方はターミナル、Windowsの方はコマンドプロンプト上で実行することでインストールが出来ます。
pip install pandasJupyter Notebookをお使いの方は、起動したNotebookのセルに、先頭に!マークをつけて実行することでインストールすることが出来ます。
!pip install pandasデータ型(pandasの基本データ型)
PandasはNumPyをベースとして構築されているため、NumPyのndarrayとの相性が良いです。2つのデータ型でデータを保持します。
1.シリーズ(Series)
2.データフレーム(DataFrame)
それぞれ1つ1つ見ていきましょう。
シリーズ
Seriesは1列や1行分のみのデータ型です。
import pandas as pd
s1 = pd.Series([1,2,3,5])
print(s1)
"""
# 左の列は行ラベル
" 右の列はシリーズのデータ
0 1
1 2
2 3
3 5
dtype: int64 # データの型
"""シリーズはデータ(values)とそれに対応する行ラベル(index)を持つ1次元データ構造であり、辞書型とは違ってデータには順番があります。
データフレーム
データフレームは2次元のラベル付きのデータ構造で、Pandasでは最も多く使われるデータ型です。
データフレームのイメージとして、スプレッドシートやSQLのテーブルをイメージするとわかりやすいです。DataFrameは複数の列を持ち、DataFrameから1列を抽出した場合も勝手にSeriesになります。また、シリーズと同様に様々な型のデータを保持することが出来ます。
import pandas as pd
df = pd.DataFrame({
'名前' :['田中', '山田', '高橋'],
'役割' : ['営業部長', '広報部', '技術責任者'],
'身長' : [178, 173, 169]
})
print(df)
print(df.dtypes)
print(df.columns) # 列ラベルの確認(辞書型のkeyが列ラベル)データフレームは、リスト型のデータを持つ辞書型をDataFrame関数の引数に渡すことで、データフレームを生成することが出来ます。保持されるデータの列の順序ですが、列ラベルによって自動的にソートされます。ですので、データを与えた時点での順序と異なってしまう可能性があるので注意です。ですが、columns引数に列の順序を指定することでその通りに作成可能です。
import pandas as pd
data = {
'名前' :['田中', '山田', '高橋'],
'役割' : ['営業部長', '広報部', '技術責任者'],
'身長' : [178, 173, 169]
}
df = pd.DataFrame(data, columns=["名前", "役割", "身長"]) # データフレーム生成時に対応するデータを持っていない場合、そのデータの列にはNaNが割り当てられます。
# また下記のようにすることで、カラムの名称を変更・置換可能です
df.columns = ["Name", "Position", "height"]
print(df)head()とtail()
Pandasのデータの中身を見る際にhead()を使うと先頭から5件を表示してくれます。また引数に数字を渡すことでその件数分先頭から取得可能です。また、tail()を使うと末尾から5件を取得できます。head()と同じように、引数に数字を渡すことでその件数分末尾から取得可能です。またデータの先頭と末尾から同時にデータを確認することも可能です。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(20,2))
df.head() # 先頭から5件
df.tail() # 末尾から5件様々な基本統計量
様々な基本統計量に関して学んで行きます。ここでは数式も出てくるので、じっくり読み進めて行ってください。
例えば、以下のような例題を考えましょう。(例題)ある企業Aでは、新規顧客獲得のために広告としてTwitter, Facebookを用いている。以下のデータはTwitter, Facebookからの曜日毎のコンバージョン数を表している。
どちらの広告媒体がどう適しているか考察せよ。なお、1コンバージョンは、広告媒体から1度の新規申し込みが来たことを表す。
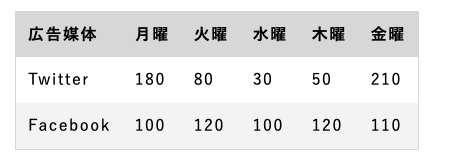
こういった生の数字だけを見せられた時に、基本統計量が役にたちます。基本統計量とは「データの特徴を要約した数値」の事を表します。まずは、幾つかの統計量の定義について紹介していきます。
そしてPythonで統計量を求め、そのデータから定量的にどのようなことが言えるか考えましょう。今回説明する基本統計量は以下の通りです。
- 平均値
- 最小値
- 最大値
- 中央値
- 最頻値
- 平方和
- 分散
- 標準偏差上記の基本統計量には、大きく代表値と散布度に大別できます。
代表値とは、データ全体を表す値で、平均値、最小値、最大値、中央値、最頻値が該当します。
散布度とは、データの散らばりを表す値で、分散、標準偏差、範囲、歪度、尖度などが該当します。
平均値
データの合計を個数で割った値。
最小値
データに含まれる最も小さい値。
最大値
データに含まれる最も大きい値。
範囲(レンジ)
最大値と最小値の差。
中央値
データを小さいものから大きいもの順に並べたとき中央に位置する値。
実際にTwitter, Facebookのコンバージョン数の基本統計量を求めてみましょう。
Pythonでの実装方法は次の通りです。
import numpy as np
twitter = np.array([180, 80, 30, 50, 210])
facebook = np.array([100, 120, 100, 120, 110])
# 平均値を計算
t_mean = np.mean(twitter)
f_mean = np.mean(facebook)
# 最小値を計算
t_minimum = np.min(twitter)
f_minimum = np.min(facebook)
# 最大値を計算
t_maximum = np.max(twitter)
f_maximum = np.max(facebook)
# 範囲を計算
t_range = t_maximum - t_minimum
f_range = f_maximum - f_minimum
# 中央値を計算
t_median = np.median(twitter)
f_median = np.median(facebook)
print("平均値(Twitter, Facebook):(" + str(t_mean) + "," + str(f_mean) + ")")
print("最小値(Twitter, Facebook):(" + str(t_minimum) + "," + str(f_minimum) + ")")
print("最大値(Twitter, Facebook):(" + str(t_maximum) + "," + str(f_maximum) + ")")
print("範囲(Twitter, Facebook):(" + str(t_range) + "," + str(f_range) + ")")
print("中央値(Twitter, Facebook):(" + str(t_median) + "," + str(f_median) + ")")
# 出力結果
"""
平均値(Twitter, Facebook):(110.0,110.0)
最小値(Twitter, Facebook):(30,100)
最大値(Twitter, Facebook):(210,120)
範囲(Twitter, Facebook):(180,20)
中央値(Twitter, Facebook):(80.0,110.0)
"""基本統計量を算出した後の解釈
結果から、平均値は二つの広告で変わらないことが分かりました。なので、平均値からどちらの広告媒体を採用すべきかどうかはわかりません。データの平均値と、上限と下限の値から異常値がないこともわかります。ただ、今回のデータでは範囲がTwitter, Facebookで大きく変わります。
こういったデータ群では、データの”ばらつき”に注目することが有効です。 では、データのばらつきを表す基本統計量について説明します。意味だけを見るとほとんど同じですが、定義式が違うことに注意が必要です。データの散らばりを計算することで、定量的に「平均値周りにどれだけデータがまとまっているか」を見ることができます。
平方和
個々のデータと平均値の差を二乗した値の和。
分散
平方和を(n-1)で割ったもの。
標準偏差
分散の平方根。
上記したデータのばらつきを表す基本統計量(分散、標準偏差)をPythonで求めてみましょう。Pythonでの実装方法は次の通りです。
import numpy as np
twitter = np.array([180, 80, 30, 50, 210])
facebook = np.array([100, 120, 100, 120, 110])
# 分散を計算
t_var = np.var(twitter)
f_var = np.var(facebook)
# 標準偏差を計算
t_std = np.std(twitter)
f_std = np.std(facebook)
print("分散(Twitter, Facebook):(" + str(t_var) + "," + str(f_var) +")")
print("標準偏差(Twitter, Facebook):(" + str(t_std) + "," + str(f_std) +")")
# 出力結果
"""
分散(Twitter, Facebook):(5160.0,80.0)
標準偏差(Twitter, Facebook):(71.8331399843,8.94427191)
"""分散や標準偏差の値から、Twitterの方がFacebookよりコンバージョン数のばらつきが大きいことが定量的にわかりました。今回の場合であれば、 – 平均的に持続したコンバージョンが得たければFacebookを利用する。- 可能であれば、月曜、金曜のみTwitterの利用をして、平日だけFacebookの広告を利用する。
などが有効な広告の使い方でしょう。また、この程度の量のデータ数であれば見ただけで把握はできるのですが、このデータ数が多くなると把握が大変になります。そういった場合に有効なのが、基本統計量の計算です。また、データ数が大きくなった時に、直観的にデータを理解できるように、グラフを作成するのも有効です。
Pandasで欠損値を処理してみよう!
次の節では、少しずつ実践的な内容に入っていきます。データ分析する際に手元のデータを加工することが多々あります。ここでは欠損値データを処理する方法をPandasで学んでいきます。
欠損値の処理
Pandasには欠損値(NaN)の扱うメソッドは「dropna」、「fillna」、「isnull」、「notnull」があります。1つ1つ解説していきます。まずdropnaは指定の軸方向にデータ列を見て、欠損値(NaN)の有無に関して指定の条件を満たす場合に、そのデータ列を削除します。fillnaは欠損値を指定の値もしくは、指定の方法で埋めることができます。isnullはデータの要素ごとにNaNはTrue、それ以外をFalseとして扱い、元のデータと同じサイズのオブジェクトを返します。notnullはisnullとは逆の真偽値を返します。
import numpy as np
import pandas as pd
df = pd.DataFrame({"int": [1, np.nan, np.nan, 32],
"str": ["python", "ai", np.nan, np.nan],
"flt": [5.5, 4.2, -1.2, np.nan]})
print(df)
# df成分に対してNaNの地位をTrueとしたブールの値のデータフレームを返す
print(df.isnull()) # notnull()を使うと、TrueとFalseが逆の処理になる。
# "int"列にNaNがある行の削除
print(df.dropna(subset=["int"]))
# NaNがある行を全て削除する
print(df.dropna())
# NaNを全て0に置換する
print(df.fillna(0)) # 第一引数にmethod="ffill" 第二引数にlimtit=数字 とすることで指定した数字までは前のデータを使ってNaNを埋めることができます
df2 = pd.DataFrame({"int": [1, np.nan, np.nan, 32],
"str": ["python", "ai", np.nan, np.nan],
"flt": [5.5, 4.2, -1.2, np.nan]})
# int列だけ0で補完
df2.fillna({"int": 0}) # 特定の列に対しては辞書型を用いる
# 列ごとに異なる値を使いたい時は複数のキーを渡す。
df2.fillna({"int": 0, "str": "ai"})
# drop()など、pandasのメソッドには、axisという引数に0もしくは1を指定出来ます。
# axis=0とした場合は、行を削除し、列を削除したい場合はaxis=1とします。
# 特定の列(例えばflt)を削除
df2.drop(labels="flt",axis=1)
"""
int str
0 1.0 python
1 NaN ai
2 NaN NaN
3 32.0 NaN
"""
# 複数の列を削除
df2.drop(labels=["flt", "str"],axis=1)
"""
int
0 1.0
1 NaN
2 NaN
3 32.0
"""
# indexを指定しても、行を消すこともできます
df2.drop(index=1, axis=0)
"""
int str flt
0 1.0 python 5.5
2 NaN NaN -1.2
3 32.0 NaN NaN
"""
# 元のデータに反映して削除するにはinplaceオプションにTrueを渡します
# ※inplaceオプションをTrueにすることで、データフレームの特定のカラムなどを直接削除するという意味です。
# 読み込みに利用したデータは書き変わることはありません。
df2.drop(labels="flt", axis=1, inplace=True)
print(df2)
"""
int str
0 1.0 python
1 NaN ai
2 NaN NaN
3 32.0 NaN
"""相関分析してみよう!
続いては、相関分析をPandasで行ってみましょう。
相関分析とは
相関分析とは、2変数間の関係を数値で表現する分析方法です。
相関分析はマーケティング領域における、データ分析においてよく用いられる分析手法の1つになります。
相関と相関係数とは
相関分析の「相関」とは2つ以上の変数があるときに、それらが「どれぐらい類似しているか」という「類似度」を意味します。2つの変量の強弱を数値化したものを「相関係数」と呼びます。
「類似度」の強さを「−1から1」までの範囲を取る数字として表現され、相関係数が1に近づくほど、強い正の相関関係になり、-1に近づくほど強い負の相関関係になり、0に近づくほど相関関係が弱くなります。
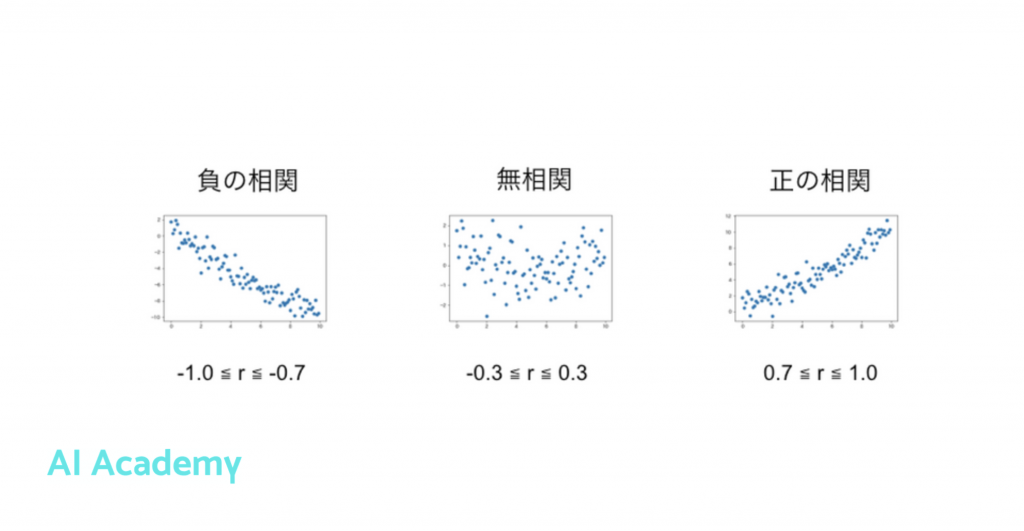
Pythonで相関係数を算出するには、pandasのcorrを使いることで、簡単に相関係数を算出できます。
Pythonで相関係数を算出してみよう
それでは、数学の点数と英語の点数のサンプルデータを用いて相関係数を求めてみます。以下のようなデータを作成します。
import numpy as np
import pandas as pd
math_score = [30, 30, 20, 90, 10]
english_score = [70, 60, 70, 100, 80]
df_math = pd.DataFrame(math_score, columns=["math_score"])
df_english = pd.DataFrame(english_score, columns=["english_score"])
df = pd.concat([df_math, df_english], axis=1)
corr = df.corr()
print(corr)それぞれの相関係数は0.747741となり、1に近いため、正の相関があることがわかります。
corr() を用いることで、広告宣伝費と売上の相関分析などに適用できます。
相関分析をする上での注意点
この記事では詳細は触れませんが、相関分析の結果から因果関係があるわけではない点注意ください。
例えば、ビールの売上とアイスの売上に高い正の相関関係があったため、アイスの販売を拡大する戦略をとれば、ビールも売れるだろう!という結論にはなりませんよね。これらには因果関係はなく、「暑い日」という共通の要因が隠れているわけです。(疑似相関)
相関分析は算出された数値を読み取れば良いため、分析しやすい手法ですが、このように相関があるから因果があるわけではないため、誤った解釈をしないように注意しましょう。
おわりに
この記事では、本記事の流れとして、Python データ分析 入門ということで、データ分析とは何か、データ分析の手順、Pythonのデータ分析ライブラリであるPandasを用いてデータ分析を体験頂きました。
この記事では学んだデータ分析として、Pandasを用いて様々な基本統計量を算出したり、データの欠損値処理をしたり、相関分析なども学びました。
Pythonは分析ツールとして非常に重宝します。今回はデータの可視化に関しての解説や、データ分析環境のJupyter NotebookやJupyter Lab、統計処理、機械学習を用いた予測モデル開発などはしておりませんが、気になった方はAI Academyなどで学んでみてください。
AI Academy Bootcampの公式LINEをご紹介します。友だち登録してくださった方に無料講義や無料動画のご案内、いまなら受講割引クーポンのプレゼントもございます。
無料で始めるチャンスです!

関連記事
関連:データ分析で必須のPandasを入門しよう!
関連:DataFrameの[]と[[]]に関して
関連:Pandas 2つのデータフレームの中から重複しないデータのみを抽出する
関連:Pandas 特定の文字列を含む行を抽出する
関連:Pandasデータ結合入門 merge、join、concat の違いを解説!
Pythonやデータ分析を効率よく学ぶには?
データ分析を効率よく学ぶには、普段からPythonを利用している現役のデータサイエンティストや機械学習エンジニアに質問できる環境で学ぶことです。
質問し放題かつ、体系的に学べる動画コンテンツでデータ分析技術を学びたい方は、オンラインで好きな時間に勉強できるAI Academy Bootcampがオススメです。受講料も業界最安値の35,000円(6ヶ月間質問し放題+オリジナルの動画コンテンツ、テキストコンテンツの利用可能)なので、是非ご活用ください。AI Academy Bootcamp では、未経験からデータサイエンティストや機械学習エンジニアを目指す方向けのプランも提供しております。詳細はこちら
おすすめ記事



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!

