

AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取る自由度調整済み決定係数とは
自由度調整済み決定係数とは、決定係数の欠点である説明変数を増やしてしまうと、数値が意味もなく大きくなる点を改善した手法です。重回帰分析において、変数の数に応じて決定係数が小さくなるように補正されます。
自由度調整済み決定係数を算出する
sklearnには実装されていないため、独自関数を実装するか、もしくはstatsmodelsライブラリを利用します。
summary関数のAdj. R-squaredの部分を参考にすることが出来ます。
import statsmodels.api as sm
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
x = boston.data
x = pd.DataFrame(x, columns=boston.feature_names)
y = boston.target
y = pd.DataFrame(y, columns=["target"])
df = pd.concat([x, y], axis=1)
x = df[["RM", "AGE", "DIS"]]
# 全要素が1のconst列(切片)を説明変数の先頭に追加
X = sm.add_constant(x)
#モデルの設定
model = sm.OLS(y, X)
# 学習
results = model.fit()
# 結果の表示
print(results.summary())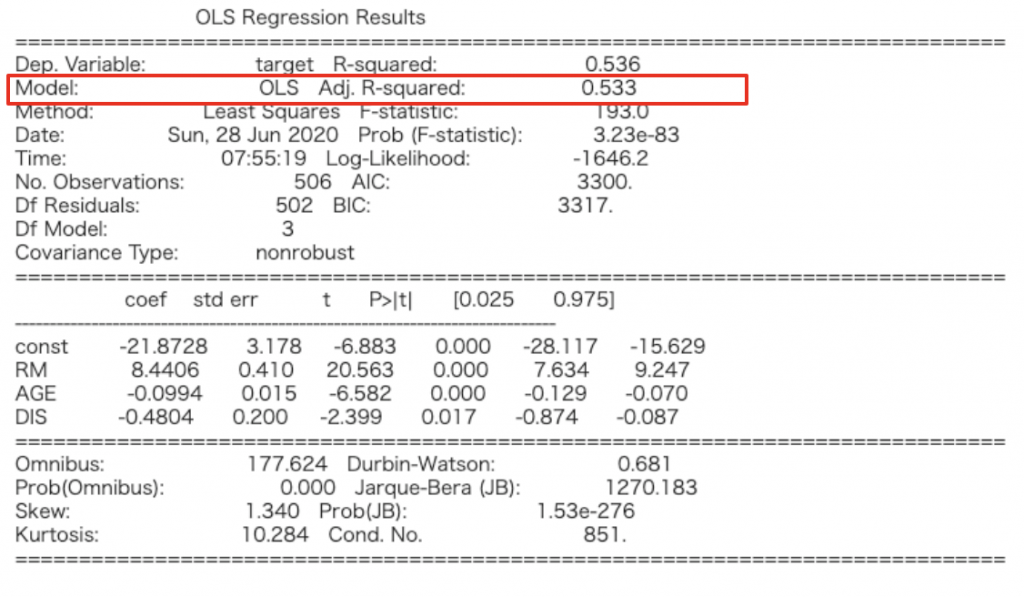
機械学習や統計を効率よく学ぶには?
機械学習や統計を効率よく学ぶには、普段から機械学習や統計学を用いて業務をしている現役のデータサイエンティストに質問できる環境で学ぶことです。
質問し放題かつ、体系的に学べる動画コンテンツでデータ分析技術を学びたい方は、オンラインで好きな時間に勉強できるAI Academy Bootcampがオススメです。受講料も業界最安値の35,000円(6ヶ月間質問し放題+オリジナルの動画コンテンツ、テキストコンテンツの利用可能)なので、是非ご活用ください。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!

