

AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取るはじめに
この章では決定木を用いて分類を行い、木を出力しますが、Windows OSの環境の場合、うまく木が出力されない場合があります。
その場合は、この章の学習した結果を可視化するをよくお読みいただけますと幸いです。
また、Pythonのバージョンやライブラリのバージョンによって、Warningなどが表示される場合があります。
決定木とは
回帰などの線形モデルやSVMでは、そのモデルがどのように分類されたかわからない分類過程がブラックボックスの手法でした。
しかし、ときには分類過程を知ることが必要になります。
例えば、メールがスパムメールかそうでないかを分類する例を考えると
今までの学習手法だとどの単語によってスパムメールと判断されたかがわかりません。
なので、スパムメールに含まれる単語を見つけるには分類過程を知る必要があります。
今回学習する決定木の一番の特徴は、分類過程が明瞭ということです。
決定木はとても単純な手法ですが、非常に効果的な教師あり学習手法です。
決定木の簡単な例を示します。
最初に、そのメールの文書に「無料」という単語が含まれているかを問います。
もし、含まれているならそのメールはスパムと分類されます。
含まれていないなら、さらにそのメールは連絡先に入っている人から来たかという質問をします。
それが、Yesならばスパムメールではない、Noならスパムメールと分類されます。
このように決定木は人が理解するのに容易で、何がその分類を決定づけたかが分かります。
訓練データのダウンロード
決定木の実装例をタイタニック号の生死データを使って示します。
今回は、タイタニックで生き延びたか生き延びられなかったかを分類します。
データページ
1.上記のサイトにアクセス
2.右クリックを押して「名前をつけて保存」
※右クリック出来ない場合(もしくは「名前をつけて保存」が出てこない場合)は、titanic.txtの内容を全て選択し、コピーし、テキストエディタやメモ帳等にペースト(貼り付け)し、「titanic.csv」というファイル名で保存してください。
3.プログラムと同じフォルダ内で、「titanic.csv」として保存
以上で完了です!
Google ColabでCSVファイルをアップロードする方法
Gogole Colabで実行する場合、先ほど.csv拡張子で保存したファイルをアップロードする必要があります。
以下の手順でアップロードが出来ます。
主に3つの流れで可能です。
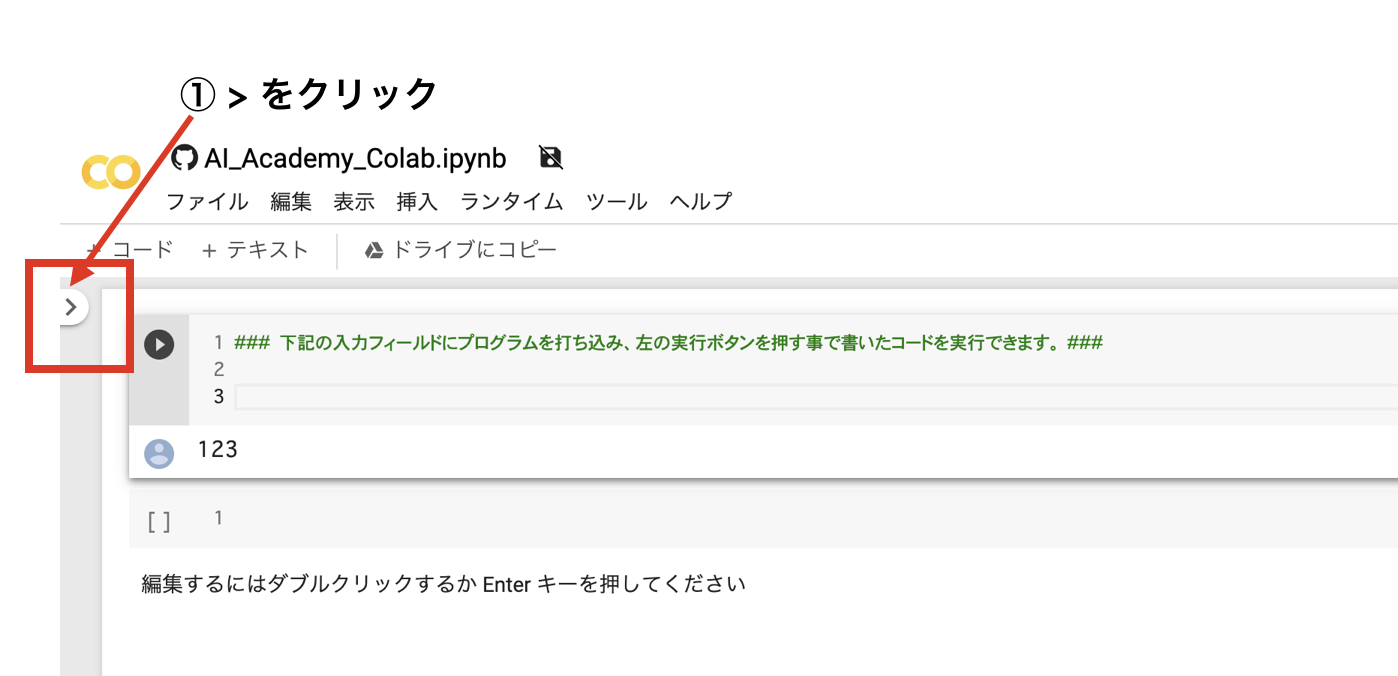
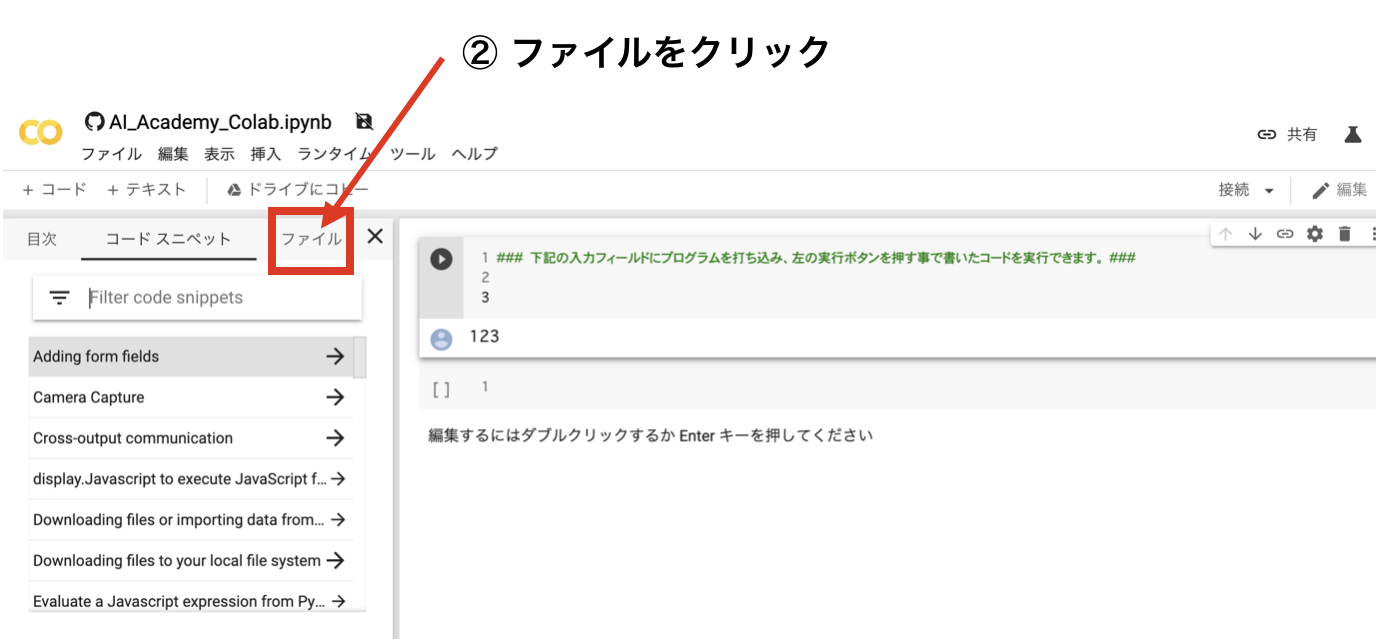
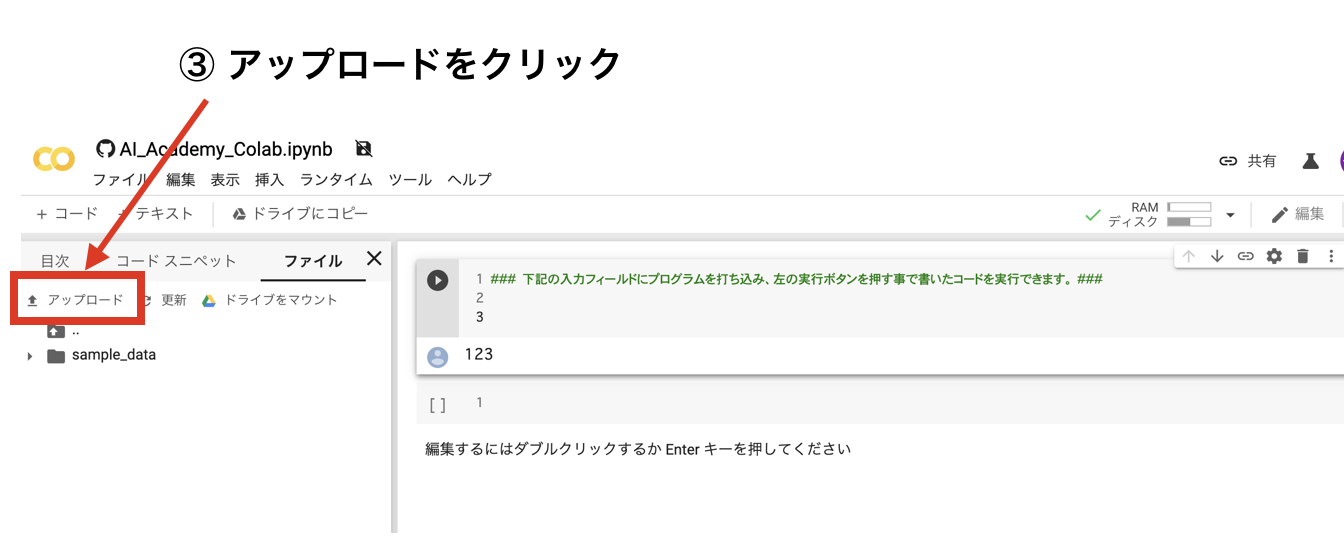
① Colabを開き、左側の >ボタンをクリックする
②左メニューのファイルをクリックをクリックする
③『↑アップロード』をクリックし、csvファイルを選択しアップロードする
CSVファイルを読み込むプログラムの実行
では、先ほどダウンロードしたtitanic.csvファイルをPythonから読み込んで見ましょう。
import csv
import numpy as np
with open('./titanic.csv','r') as csvfile:
titanic_reader = csv.reader(csvfile,delimiter=',',quotechar='"')
#特徴量の名前が書かれたHeaderを読み取る
row = next(titanic_reader)
feature_names = np.array(row)
#データと正解ラベルを読み取る
titanic_x, titanic_y = [],[]
for row in titanic_reader:
titanic_x.append(row)
titanic_y.append(row[2]) #正解ラベルは3列目の"survived"
titanic_x = np.array(titanic_x) #型をリストからnumpy.ndarrayにする
titanic_y = np.array(titanic_y) #型をリストからnumpy.ndarrayにする
print(feature_names)
print(titanic_x[0],titanic_y[0])
上のプログラムを実行すると、次のように特徴量と1番目のdataの中身が出力されます。
['row.names' 'pclass' 'survived' 'name' 'age' 'embarked' 'home.dest' 'room'
'ticket' 'boat' 'sex']
['1' '1st' '1' 'Allen, Miss Elisabeth Walton' '29.0000' 'Southampton'
'St Louis, MO' 'B-5' '24160 L221' '2' 'female'] 1
前処理 / 特徴量選択
最初に、今回使う特徴量を選択します。
まず、前処理の説明です。
前処理とは、生データからその特徴を数値で表した「特徴量」にすることです。
機械学習の観点ではテキストデータは役に立たず、意味のある数値に変換できて初めてクラスタリング等の機械学習アルゴリズムに入力することができます。
そして、特徴量とは、入力の使用するデータのことであり回帰の章では説明変数と呼んでいました。
今回は、特徴量として「クラス」「年齢」「性別」を使用します。
# class(1),age(4),sex(10)を残す
titanic_x = titanic_x[:,[1, 4, 10]]
feature_names = feature_names[[1, 4, 10]]
print(feature_names)
print(titanic_x[12],titanic_y[12])
実行すると、以下の内容が出力されます。
['pclass' 'age' 'sex']
['1st' 'NA' 'female'] 1
欠損値の補完
出力した13番目のデータを見ると、ageが’NA’となっています。
これはデータがNot Available、すなわち存在しないということを表しており欠損値と呼ばれます。
欠損値があると学習できないため、今回は欠損値を年齢の平均値に置き換えます。
(欠損値を埋めるために最頻値や中央値を用いることもあります)
# 年齢の欠損値を平均値で埋める
ages = titanic_x[:,1]
#NA以外のageの平均値を計算する
mean_age = np.mean(titanic_x[ages != 'NA',1].astype(float))
#ageがNAのものを平均値に置き換える
titanic_x[titanic_x[:, 1] == 'NA',1] = mean_age
LabelEncoder
また、出力した13番目のデータのsexは’female’と文字列となっています。
文字列のデータのことをカテゴリカルデータといいます。
学習するためには、文字列を数値に修正する必要があります。
そこで、LabelEncoder()を使って数値に直します。
数値に直すというのは、
‘female’ → 0
‘male’ → 1
にするということです。
from sklearn.preprocessing import LabelEncoder
enc = LabelEncoder()
label_encoder = enc.fit(titanic_x[:, 2])
print('Categorical classes:',label_encoder.classes_)
integer_classes = label_encoder.transform(label_encoder.classes_)
print('Integer classes:',integer_classes)
t = label_encoder.transform(titanic_x[:, 2])
titanic_x[:,2] = t
print(feature_names)
print(titanic_x[12],titanic_y[12])
実行すると、下記のように出力され’female’が0になっていることが分かります。
['pclass' 'age' 'sex']
['1st' '31.19418104265403' '0'] 1
OneHotEncoder
先程は、’sex’を0,1に変更しました。
しかし、pclassもカテゴリカルデータなので数値に修正する必要があります。
ただし、ageと同様の手法で
1st → 0
2nd → 1
3rd → 2
としてはいけません。
なぜなら、カテゴリカルデータでは順序性がなく1st < 2nd < 3rdという関係が成り立たないからです。
これを、数値の1, 2, 3としてしまうと1 < 2 < 3という関係になってしまいおかしくなっています。
そこで、OneHotEncoderという手法を用います。
これは、それぞれのデータに対し当てはまれば「1」当てはまらなければ「0」とするものです。
*(注意)今回、pclass(階級)に対して、OneEncoderを用いますが、
階級は、順序ありデータ(順序尺度)ではありますが、今回の目的は、タイタニック号のデータから、死んだか生き延びたかを予測するモデルを作る上で考えると順序は関係なくなります。
例えば、年収が1000万以上かどうか分類するモデルの場合、pclass(階級)は順序ありデータのLabelEncoderにしますが、生きるか死ぬかの分類モデルの場合ですので、pclassは順序関係ないと考えられます。
実際、LabelEncoderでも可能ですが、モデルの性能を考えたときに、最適な前処理は、OneHotEncoderを選択しています。
たとえば、A〜D君の好きな果物が下の表であるとします。
| 人物 | 好きな果物 |
|---|---|
| A | りんご |
| B | ばなな |
| C | ぶどう |
| D | りんご |
これに対し、OneHotEncoderを行うと
| 人物 | りんご | ばなな | ぶどう |
|---|---|---|---|
| A | 1 | 0 | 0 |
| B | 0 | 1 | 0 |
| C | 0 | 0 | 1 |
| D | 1 | 0 | 0 |
となり自分が当てはまる項目は1、当てはまらない項目は0となります。
では、pclassに対しOneHotEncoderを行なってみましょう。
from sklearn.preprocessing import OneHotEncoder
enc = LabelEncoder()
label_encoder = enc.fit(titanic_x [:, 0])
print("Categorical classes:", label_encoder.classes_)
integer_classes = label_encoder.transform(label_encoder.classes_).reshape(3, 1)
print("Integer classes:", integer_classes)
enc = OneHotEncoder()
one_hot_encoder = enc.fit(integer_classes)
#最初に、Label Encoderを使ってpclassを0-2に直す
num_of_rows = titanic_x.shape[0]
t = label_encoder.transform(titanic_x[:, 0]).reshape(num_of_rows, 1)
#次に、OneHotEncoderを使ってデータを1, 0に変換
new_features = one_hot_encoder.transform(t)
#1,0になおしてデータを統合する
titanic_x = np.concatenate([titanic_x, new_features.toarray()], axis = 1)
#OnehotEncoderをする前のpclassのデータを削除する
titanic_x = np.delete(titanic_x, [0], 1)
#特徴量の名前を更新する
feature_names = ['age', 'sex', 'first class', 'second class', 'third class']
# Convert to numerical values
titanic_x = titanic_x.astype (float)
titanic_y = titanic_y.astype (float)
print(feature_names)
print(titanic_x[0],titanic_y[0])
実行すると、以下のようになりデータが全て数値になっていることが分かります。
これで学習をすることができるようになりました。
['age', 'sex', 'first class', 'second class', 'third class']
[ 29. 0. 1. 0. 0.] 1.0
学習
まずは、データを学習データとテストデータに分けます。
その後、scikit-learnのDecision Tree Classifierを使って学習します。
# sklearn 0.20から下記は廃止されます
# from sklearn.cross_validation import train_test_split
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(titanic_x,titanic_y, test_size=0.25, random_state=33)
# 次にscikit-learnのDecision Tree Classifierを使って学習します。
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth= 3, min_samples_leaf = 5)
clf = clf.fit(x_train, y_train)
# 今回は、パラメータとしてcriterion, max_depth, min_samples_leafを指定します。
"""
criterion・・・ 分類基準(entropyとginiがある)
max_depth・・・ 木の深さ
min_samples_split・・・ 分割するときに必要なデータ数
"""
これ以外のパラメータを設定したいとき、scikit-learnのHP(DecisonTreeClassfier)を参考にしてみましょう。
これで学習ができました。
学習した結果を可視化する
では、学習した結果を可視化してみましょう。
決定木を可視化するには、Graphvizとpydotplusが必要になります。
ターミナル(コマンドプロンプト)からインストールしましょう。
pip install Graphviz
pip install pydotplus
※インストールできない場合はこちらからインストールしてください。
またInvocationException: GraphViz’s executables not foundというエラーで可視化ができない場合は、以下のようにしてみてください。
brew install graphviz
pip install -U pydotplus
ダウンロードサイト1
ダウンロードサイト2
※上記の方法かつWindowsで出来ない場合は、ネットの情報を参考にしてみてください。
そして、以下のプログラムを入力すると木が出力されます。
import pydotplus
from sklearn.externals.six import StringIO
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,feature_names = ['age','Sex','1st_c1ass','2nd_class','3rd_class'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf")
この木は、学習データによる学習結果を表しています。
質問を答えることによって、分類がされます。
例えば、一番上の部分では
sex <= 0.5か?ということを聞いています。
(sexは’woman’か?)
このとき、答えがyesなら左へ、Noなら右へ進みます。
進んだ先の質問にも答え、同様にyesなら、左へNoなら右に行きます。
これを最下段まで繰り返し、最下段と多数のほうの正解ラベルがふられます。
sex <= 0.5 (sexは’woman’か) → yes
3rd_class <= 0.5 (3rd_classではない) → yes
1st_class <= 0.5 (1st_classではない) → yes
と進んだとき、最後はValue = [8, 70]となっており、生き延びた人のほうが多いです。
なので、性別が女性で、2nd classにいた人は生き延びたと分類されます。
では、first classにいた10才の女の子はどちらに分類されるか自分で考えてみましょう。
答えは、”生き延びた”です。
では、最後に精度を確認してみましょう。
下記一行を追加してください。
# 決定木モデルの評価
measure_performance(x_train, y_train, clf)
追加後に実行すると次のような出力になります。
Accuracy:0.838
Classification report
precision recall f1-score support
0.0 0.82 0.98 0.89 662
1.0 0.93 0.55 0.69 322
avg / total 0.85 0.84 0.82 984
Confussion matrix
[[649 13]
[146 176]]
以上確認すると、なかなかに良い分類ができていることが分かります。
今回作成したプログラム
import csv
import numpy as np
with open('./titanic.csv','r') as csvfile:
titanic_reader = csv.reader(csvfile,delimiter=',',quotechar='"')
#特徴量の名前が書かれたHeaderを読み取る
row = next(titanic_reader)
feature_names = np.array(row)
#データと正解ラベルを読み取る
titanic_x, titanic_y = [],[]
for row in titanic_reader:
titanic_x.append(row)
titanic_y.append(row[2]) #正解ラベルは3列目の"survived"
titanic_x = np.array(titanic_x) #型をリストからnumpy.ndarrayにする
titanic_y = np.array(titanic_y) #型をリストからnumpy.ndarrayにする
print(feature_names)
print(titanic_x[0],titanic_y[0])
# class(1),age(4),sex(10)を残す
titanic_x = titanic_x[:,[1, 4, 10]]
feature_names = feature_names[[1, 4, 10]]
print(feature_names)
print(titanic_x[12],titanic_y[12])
# 年齢の欠損値を平均値で埋める
ages = titanic_x[:,1]
# NA以外のageの平均値を計算する
mean_age = np.mean(titanic_x[ages != 'NA',1].astype(float))
# ageがNAのものを平均値に置き換える
titanic_x[titanic_x[:, 1] == 'NA',1] =mean_age
from sklearn.preprocessing import LabelEncoder
enc = LabelEncoder()
label_encoder = enc.fit(titanic_x[:, 2])
print('Cateorical classes:',label_encoder.classes_)
integer_classes = label_encoder.transform(label_encoder.classes_)
print('Integer classes:',integer_classes)
t = label_encoder.transform(titanic_x[:, 2])
titanic_x[:,2] = t
print(feature_names)
print(titanic_x[12],titanic_y[12])
from sklearn.preprocessing import OneHotEncoder
enc = LabelEncoder()
label_encoder = enc.fit(titanic_x [:, 0])
print("Categorical classes:", label_encoder.classes_)
integer_classes = label_encoder.transform(label_encoder.classes_).reshape(3, 1)
print("Integer classes:", integer_classes)
enc = OneHotEncoder()
one_hot_encoder = enc.fit(integer_classes)
# 最初に、Label Encoderを使ってpclassを0-2に直す
num_of_rows = titanic_x.shape[0]
t = label_encoder.transform(titanic_x[:, 0]).reshape(num_of_rows, 1)
# 次に、OneHotEncoderを使ってデータを1, 0に変換
new_features = one_hot_encoder.transform(t)
# 1,0になおしてデータを統合する
titanic_x = np.concatenate([titanic_x, new_features.toarray()], axis = 1)
# OnehotEncoderをする前のpclassのデータを削除する
titanic_x = np.delete(titanic_x, [0], 1)
# 特徴量の名前を更新する
feature_names = ['age', 'sex', 'first class', 'second class', 'third class']
# Convert to numerical values
titanic_x = titanic_x.astype (float)
titanic_y = titanic_y.astype (float)
print(feature_names)
print(titanic_x[0],titanic_y[0])
# sklearn 0.20から下記は廃止されます。
# from sklearn.cross_validation import train_test_split
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(titanic_x, titanic_y, test_size=0.25, random_state=33)
from sklearn import metrics
def measure_performance(x,y,clf, show_accuracy=True,show_classification_report=True, show_confussion_matrix=True):
y_pred=clf.predict(x)
if show_accuracy:
print("Accuracy:{0:.3f}".format(metrics.accuracy_score(y, y_pred)), "\n")
if show_classification_report:
print("Classification report")
print(metrics.classification_report(y, y_pred), "\n")
if show_confussion_matrix:
print("Confussion matrix")
print(metrics.confusion_matrix(y, y_pred),"\n")
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth= 3, min_samples_leaf = 5)
clf = clf.fit(x_train, y_train)
import pydotplus
from sklearn.externals.six import StringIO
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,feature_names = ['age','Sex','1st_c1ass','2nd_class','3rd_class'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf")
# 決定木モデルの評価
"""
【決定木モデルの評価に関しての補足】
決定木モデルの評価に関してmeasure_performance(x_train, y_train, clf)
とありますが、testに対してではなくtrainで行っています。
一般的に汎化性能は学習に使用したデータとは独立なもので図るべきですが、しっかりと学習できたか、ということを見るのにtrainでの性能も出すことがあります。
trainだけで性能の評価はしません。
testだけの場合もありますが、trainでちゃんと学習できている(これは汎化性能ではなく、少なくともtrainデータにはfitできている)ということを確認した上で、testで汎化性能を確認します。
なお正確には交差判定やAIC, BIC, WAIC,SBIC等の情報量基準でのモデルの汎化性能を確認しますが、DNNのように計算コストが高いモデルの場合は、train, valid, testというふうに元のデータを分割し、validでの性能を確認しながらtrainによってモデルのパラメータチューニングを行なっていきます。
"""
measure_performance(x_train, y_train, clf)
まとめ
この記事では、決定木に関して学びました。
決定木の最大の利点は分類過程が見れることです。
データ分析業務でも用いる機会が多いため、しっかり使えるようにしておきましょう。
Pythonや機械学習を効率よく学ぶには?
Pythonや機械学習を効率よく学ぶには、普段からPythonを利用している現役のデータサイエンティストや機械学習エンジニアに質問できる環境で学ぶことです。
質問し放題かつ、体系的に学べる動画コンテンツでデータ分析技術を学びたい方は、オンラインで好きな時間に勉強できるAI Academy Bootcampがオススメです。受講料も業界最安値の35,000円(6ヶ月間質問し放題+オリジナルの動画コンテンツ、テキストコンテンツの利用可能)なので、是非ご活用ください。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!
