

AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取るはじめに
このテキストでは、一般的な機械学習手法とディープラーニングの違いを理解して頂くために、ディープラーニング(深層学習)の説明に関して概要のみを簡単に説明致します。
そのためディープラーニングの内部構造に関してしっかり学びたい方は、他のテキスト(ニューラルネットワークの理論と実装など)をご確認ください。
ディープラーニングとは
ディープラーニング(deep learning / 深層学習)は階層の深いニューラルネットワークを利用したアルゴリズムの総称をさし、脳(神経細胞)の働きを模した学習アルゴリズムで、一般的に中間層(隠れ層/Hidden Layers)が2層以上のニューラルネットワークをディープラーニングと呼びます。
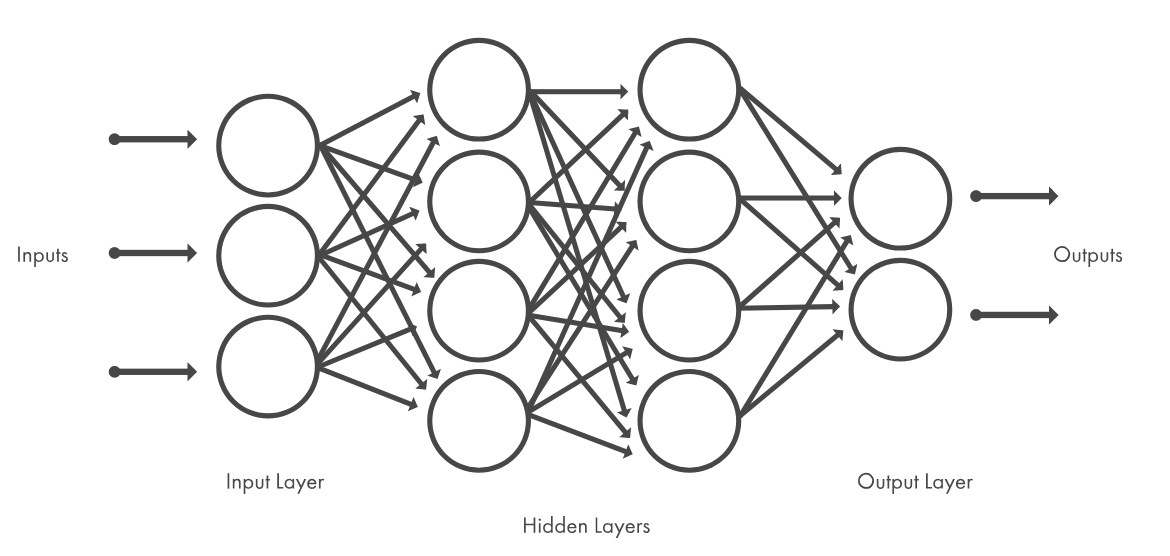
引用: https://jp.mathworks.com/discovery/deep-learning.html
ディープラーニングは中間層を多層にしたことで、学習するべきパラメータ数が大幅に増えたことで、予測精度が向上しました。
実際のところディープラーニングの基本的な機械学習アルゴリズムであるニューラルネットワークの歴史は古く、1960年代からすでに存在していましたが、
当時では、多数のパラメータを必要とする非線形の問題に対して非常に学習が困難かつ膨大な時間がかってしまいました。
あれから50年以上が経過し、クラウドコンピューティングの発展などにより、GPUなどのコンピュータ資源が利用しやすくなったことや、膨大なデータがインターネット上に増えたことで、ディープラーニングを活用出来るようになりました。
機械学習とディープラーニングの違い
従来の機械学習において非常に難しかったこととしては、特徴量(変数)の設計です。
例えば、従来の画像認識では、入力データはピクセル値そのものではなく、「特徴量」と呼ばれる変数の集合でしたが、画像の特徴量は色、形状、テクスチャといった様々な情報を表現した変数のセットであることが一般的です。
この特徴量の設計というのは非常に難しく、研究者の経験や直感によるところが大きくまさに職人芸でした。
一方で、ディープラーニングは、そのような特徴量もデータから自動的に学習することが可能になりました。
また、ディープラーニングは機械学習アルゴリズムの1手法で、分類や回帰ができます。

ディープラーニングは何がすごいのか
つまり、これまで手動で行っていた特徴量の設定を、データに基づいて最適なものを自動的に生成してくれるようになった点です。
そのため、ディープラーニングの登場により、再び3度目のAIブームがきたと言われております。
この点が、従来の機械学習技術と大きく違う点ですが、上記に加え、
深層学習では大量のデータを学習した時に高い汎化能力が出ます。
(※汎化能力というのは学習データではなく、未知データに対して正解することができる能力のことです。)
ですので、十分な質かつ大量のデータがない場合には、高い汎化能力がでない場合がありますので注意です。
まとめ
この章では、ディープラーニングとは何か、機械学習とディープラーニングの違いや、ディープラーニングの何がすごいのかを学びました。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!

