Vision Transformerとは
Vision Transformer(ViT)とは、画像認識にTransfomerを利用したモデルです。
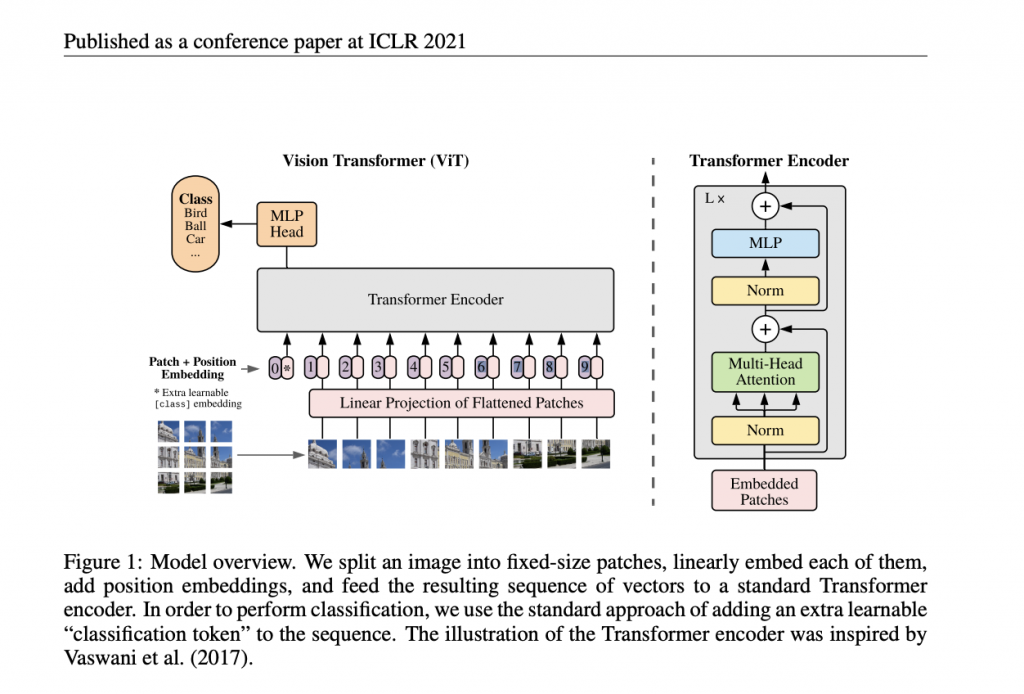
論文より引用
2020年にGoogleから発表されました。
Vision Transformerでは、Transformerのみを利用しているモデルで、
特徴として畳み込みを用いずにSOTA(State-of-the-Art)を達成(現時点での最先端レベル)したことで注目されました。
大枠の処理として、入力画像をベクトルに変換した後に、Transformer Encoderにより処理し、MLPヘッドで処理するといった流れになります。
アーキテクチャの詳細は論文や書籍を参考にしたり、もしくはKerasでViTのモデルを参考に実装しながら理解を深めてみてください。
AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取るまとめ
Vision Transformerの特徴として、CNNを用いずTransfomerのみを利用した画像認識モデルであることを紹介しました。
画像認識を効率よく身につけるには
画像認識を学ぶ上でおすすめなのは、画像認識分野を専門とする機械学習エンジニアからいつでも質問できる環境で学ぶことが大切です。
AI Academy Bootcampなら、6ヶ月35,000円にてチャットで質問し放題の環境で、機械学習やデータ分析が学べるサービスを提供しております。
数十名在籍しているデータサイエンティストや機械学習エンジニアに質問し放題の環境でデータ分析、統計、機械学習、SQL等が学べます。
物体検出やセグメンテーションに必要なスキルを効率よく体系的に身に付けたい方は是非ご検討ください。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!