

AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取る特徴量のスケーリングとは
特徴量のスケーリングとは、機械学習の前処理の1つで、標準化と正規化が代表例です。
標準化は「平均を0、分散を1とするスケーリング手法」で、正規化は「最小値を0、最大値を1とする0-1スケーリング手法」です。このようなスケーリングには、特徴量によって単位が違っていたり、または値が極端に違っている時に、各次元の関係をわかりやすくするために有効です。
このサイトは、Pythonや生成AIなどを学べるオンラインプログラミングスクール AI Academy Bootcampが運営しています。
標準化とは
標準化(Standardization)は英語では”z-score normalization”と呼ばれ、元のデータの平均を0、標準偏差が1のものへと変換する手法のことを指します。
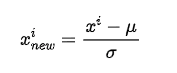
from sklearn.preprocessing import StandardScaler
# 標準化
sc = StandardScaler()
# 標準化させる値(今回は変数aが標準化する値ですが、x_trainやx_testなどの説明変数を渡します。)
a = np.random.randint(10, size=(2,5))
X_std = sc.fit_transform(a)
print("平均", X_std.mean())
print("標準偏差", X_std.std())正規化とは
正規化は英語では”min-max normalization”と呼ばれ、データは最大値が1、最小値が0のデータとなるように行われます。正規化の方法は以下の通りです。
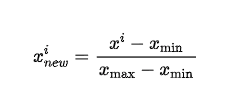
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler([0,1]) # 0~1の正規化
# 引数にdataという変数を入れた場合のコード
# X_MinMaxScaler = scaler.fit_transform(data)【無料動画:倍速で学ぶ!生成AIを活用したプログラミング勉強法(短縮版)】
生成AIを活用して効率的にプログラミングを学ぶ方法を解説しています。生成AIの基本的な仕組みや効果的な活用法、注意点についても詳しく説明。勉強法とともに生成AIそのものについても学べる内容となっています。ぜひご覧ください!
全編は、AI Academy公式LINEで配信中です。

標準化と正規化の使い分け
標準化と正規化の特徴を確認しましょう。
標準化では、データを平均0、標準偏差が1になるように変換する正規化法でしたが、一般的に標準化を用いる場合は、最大値及び最小値が決まっていない場合や外れ値が存在する場合に利用します。基本的には正規化ではなく、標準化を利用する事が多いです。正規化の場合は、外れ値が大きく影響してしまうためです。一方、正規化では主に0、1の範囲内にスケーリングしますが、最大値及び最小値が決まっている場合などに利用します。画像処理などでは学習コストを下げる事ができるため、良く用いられます。
何のために標準化が必要なのか?
標準化とは、データに対して平均値が0、標準偏差が1になるように計算することでしたが、
標準化が必要なシーンとして、例えば、年齢と年収の数値があった場合に標準化をしないと、どちらかの変数を重視してしまうモデルができてしまいます。
(誤差の重みでモデルを更新した際に、年収ばかりが重要視されるモデルになってしまうでしょう。)
そこで、標準化することで、特徴量がもつ値の重みを平等にすることが出来ます。
一般的には、機械学習を用いた予測モデルを作る上で、標準化は特徴量に対して適用しておいたほうが良いでしょう。
特徴量のスケールに影響されない手法に関して
実は機械学習を用いた予測モデルを作る上で、必ずしも標準化の必要はありません。
例えば、決定木系のアルゴリズムですとスケーリングは不要です。これは決定木のアルゴリズムが各特徴量の大小関係しか見ないためです。(決定木が特徴量の数値の大小関係(順位)だけを見ていて、数値にどの程度の差があるかを見ていないため)
つまり決定木などではスケーリング自体不要になります。精度が変わることもありません。
おわりに
この記事では、特徴量のスケーリングに関して解説しました。
具体的には「標準化」と「正規化」に関して学びました。どちらもデータの前処理としてよく用いられますのでしっかり使えるようにしましょう。
✨AI人材コース 受講お申込み受付中!
AI Academy Bootcamp ではAI・データサイエンス、機械学習、Webアプリ開発の実践力を高める全6コース約50時間以上の動画が見放題!AIの学習に必須のPythonの学習から始まり、ITリテラシー、LLM学習など、目的に応じた幅広い分野をカバーしています。LINE公式では、お得な割引クーポンもプレゼントしています!
単独で学ぶより、全コースを一気に学ぶことで得られる「学習シナジー効果」が特長。
基礎から応用まで、データ分析とAI開発のスキルを効率よく身につけられます。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!

