

AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取るはじめに
この記事では、手っ取り早く機械学習プログラミングを体験することを目的としています。
そのため、Pythonプログラミングの基本文法及び、Scikit-learn(サイキットラーン)やNumPy(ナムパイ/ナンパイ)やPandas(パンダス)、Matplotlib(マットプロットリブ)といったPythonでデータ分析を行う際に必須となるライブラリの基本的な使い方や説明はこの章では割愛致しますので、ご了承ください。
上記を詳しく学びたい方はそれぞれAI Academyで学ぶことが出来ますので、この章を終えてから是非チャレンジしてみてください。
Pythonプログラミング 基本文法速習
NumPy入門
Pandas入門
Matplotlib入門
機械学習プログラミング入門編
また、現在のテキストのコードでワーニングが出る場合があります。
ワーニングは致命的なエラーではないので、動作には問題ありませんので、一旦気にせず進めてください。
Google Colaboratoryで機械学習をはじめよう!
まず前半では、Googleが機械学習の教育及び研究用に提供しているGoogle Colaboratory(グーグル・コラボレイトリー)の使い方を説明し、後半でPythonプログラミングと機械学習プログラミングを行っていきます。
今回使うGoogleのColaboratoryは、インストール不要かつ、Pythonを用いた機械学習環境が整えられているため、すぐにPythonプログラミングを始めることが可能な無料のサービスです。
費用は無料でCPU及びGPU(1回12時間)の環境が利用可能で、用意するものは、Googleアカウントさえあれば利用できます。
ノートブックの作成
「最近のノートブック」の画面が表示されますので、画面の左下から「PYTHON3の新しいノートブック」を選びクリックしてください。
または、左上メニューの『Python3 のノートブックを新規作成』でも同じように作成できます。



・左上メニューの『Python3 のノートブックを新規作成』の場合

Colaboratoryの画面が表示されましたでしょうか?
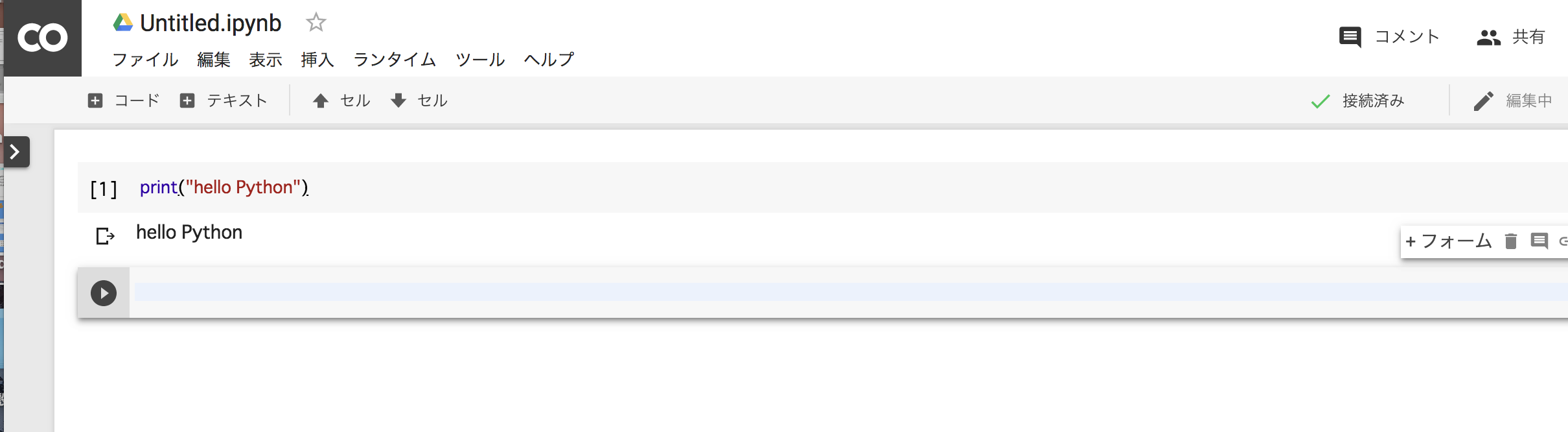
さて、黒丸の三角の実行ボタンの右横にある背景が薄い青色のテキストエディタがありますので、そこにプログラムを記述します。
(この部分をセルと呼んだりします。)
print("hello Python")
始めは少し時間がかかりますが、少し待つと結果が表示されます。
ちなみに作成したノートブックは、自動的にGoogle Driveに保存されます。
次は、Pythonのグラフ描画モジュールであるMatplotlibを使い、グラフを描画してみます。
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(0, 10, 0.1)
plt.plot(x)
plt.show()

GPUを使ってみる
ノートブック作成時には、GPUではないため、下記操作にてGPUを使えるようにします。
上部メニューの ランタイム > ランタイムのタイプを変更を選択し、ハードウェアアクセラレータをNone からGPUに変更して保存します。


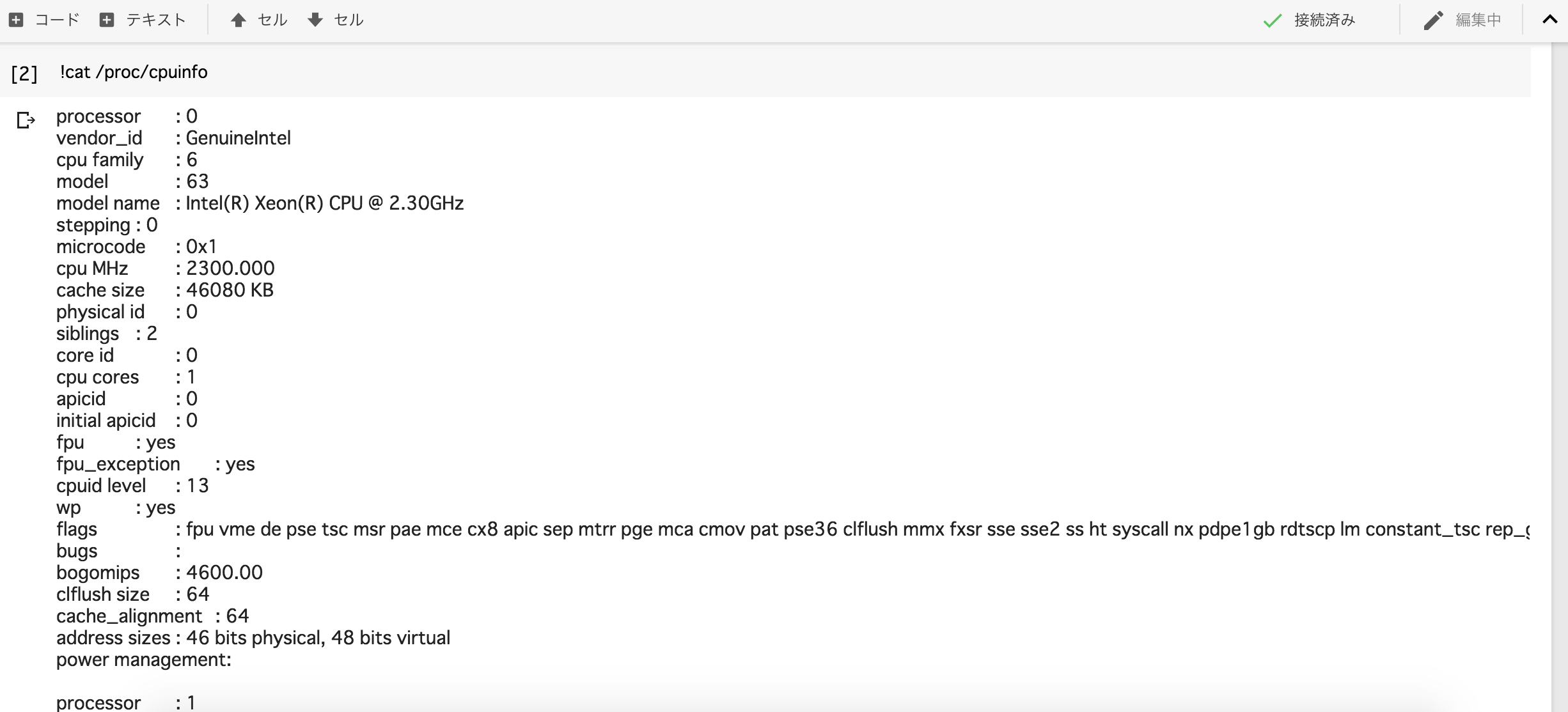
さて、下記を実行し‘/device:GPU:0’と出力されていればGPUが利用できます。

また、
!cat /proc/cpuinfo
及び、
!cat /proc/meminfo
を実行すると、Colaboratoryのマシンスペックを調べることが出来ます。
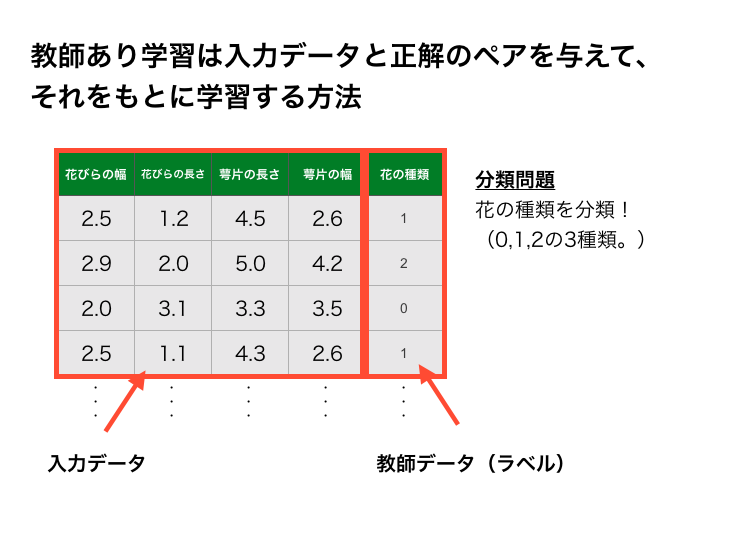
教師あり学習
機械学習には、教師あり学習、教師なし学習、強化学習の3つに分けられ、このテキストでは教師あり学習を用います。
教師あり学習は入力データと正解のペア(教師データ)を与えて、それをもとに学習する方法です。
機械学習プログラミング体験(概要)
このテキストでは、Iris(アヤメ)という花の品種を判定できる分類器を作っていきます。
上記の画像を見て分かる通り、3種類ともとてもよく似ております。
この3種類の花のうち、どの花なのかを判定するプログラムを機械学習を使って、実装していきます。
また、今回は教師あり学習を利用しますので、データにはそれぞれ、Setosa(一番右)には0、Versicolor(一番左)には1、Versinica(中央)には、2の正解ラベルが与えられています。
画像引用元: SUPPORT VECTOR MACHINE (SVM CLASSIFIER) IMPLEMENATION IN PYTHON WITH SCIKIT-LEARN
画像引用元: iris dataset
petal: 花弁
sepal: がく
アヤメの品種分類タスクは、花のがくの長さと花のがくの幅、花の花弁の長さと花の花弁の幅の4つを用いて、花の品種を分類しようというものです。
ですのでデータセットの中には、4つの測定値(特徴量)と3種類の花(Setosal、Versicolor、Versinica)がセットになったデータが150個与えられています。
| 番号 | 長さ・幅(cm) | PetalとSepal |
|---|---|---|
| 1 | Sepal Length | Sepal(がくの長さ)の長さ |
| 2 | Sepal Width | Sepal(がくの長さ)の幅 |
| 3 | Petal length | Petal(花びら)の長さ |
| 4 | petal Width | Petal(花びら)の幅 |
そして、正解値(ラベル: 花の名称)は、それぞれ下記になります。
0: Setosa
1: Versicolor
2: Versinica
くどいようですが、今回の目的は、4つの測定値がモデルに入力されたとき、花の品種を3種類(Setosa、Versicolor、Versinica)のうち、どの花に該当するのかを当てられるようにします。
次は再度、入力と出力の関係を確認しておきましょう。
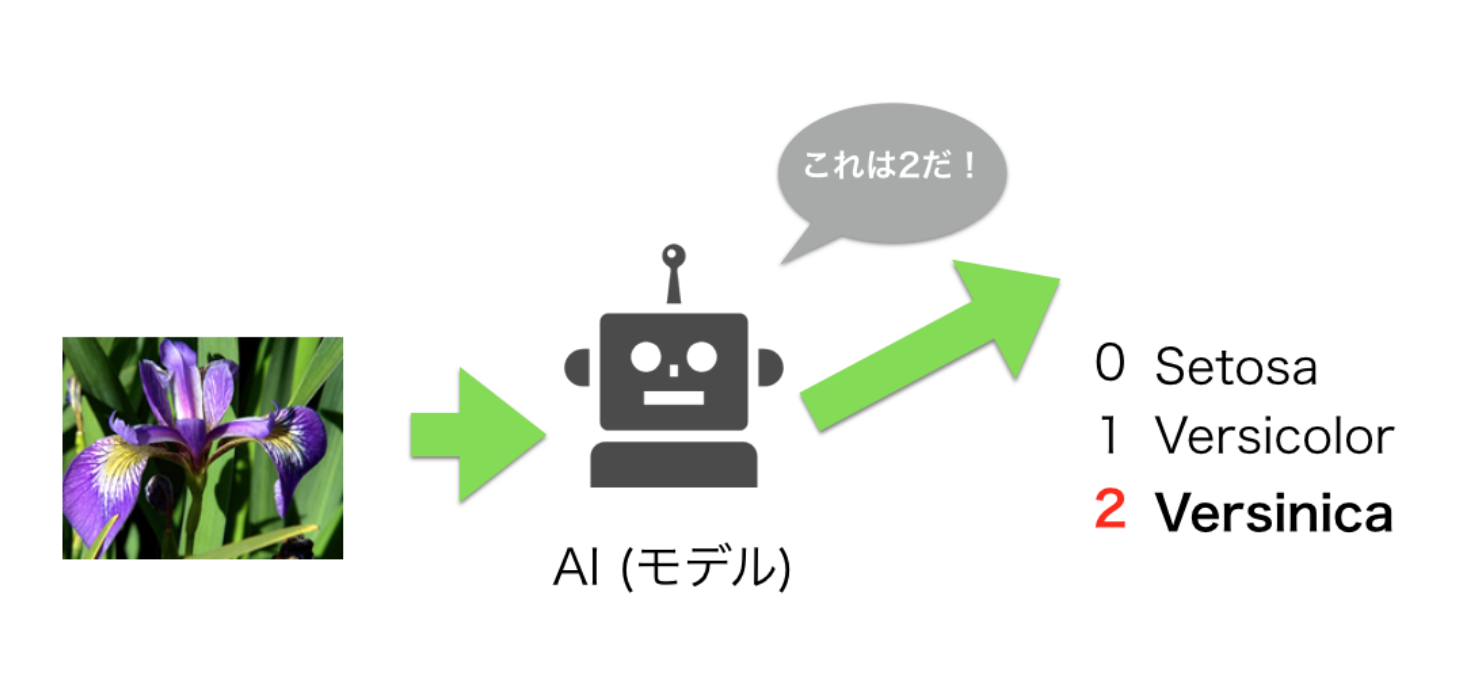
上の画像では入力に画像を入力しているようですが、実際は、がくの長さやがくの幅、花びらの長さ、花びらの幅の4つの測定値はを入力します。
例えば、入力となる4つの値が次のようになります。
入力例
| 特徴 | cm |
|---|---|
| がくの長さ(Sepal Length) | 1.4 |
| がくの幅 (Sepal Width) | 3.5 |
| 花びらの長さ (Petal Length) | 5.1 |
| 花びらの幅 (Petal Width) | 0.2 |
Pythonプログラムでは次のように書きます。
"""
次のセクション機械学習プログラミング体験(実装)で実装しますが、
以下の処理までには、データの読み込み、モデルの作成、学習といった流れを行います。
"""
model.predict([[1.4, 3.5, 5.1, 0.2]])
出力は例えば次のようになります。
例えばプログラムの出力値が2(つまりVersinicaと判定)と返ってきます。
[2]
機械学習プログラミング体験(実装)
概説は以上にし、実装をしていきます。
さて、ここではSVM(サポートベクターマシン)と呼ばれるアルゴリズムを使って分類を行ないます。
まずは、sklearnから、IrisのdatasetとSVMを読み込みます。
from sklearn import datasets
from sklearn import svm
次に、Irisが持っているデータの内容とIrisの形状を出力します。
# Irisの測定データの読み込み
iris = datasets.load_iris()
print(iris.data)
print(iris.data.shape) # 形状
出力すると、Irisには150のデータがあることがわかります。
次にデータの長さを調べてみます。
num = len(iris.data)
print(num)
では、サポートベクターマシンを記述します。
さきほどの、printの処理はコメントアウトしましょう。
"""
冒頭のはじめににも書きました通り、現在のテキストのコードでワーニングが出る場合があります。
ワーニングは致命的なエラーではないので、動作には問題ありません。そのため一旦気にせず進めてください。
"""
clf = svm.SVC(gamma="auto")
clf.fit(iris.data, iris.target)
ここで、svm.SVC()とfit()に関して説明します。
まず、svm.SVC()は、SVM(サポートベクターマシン)というアルゴリズムです。
Scikit-learnでは分類に関するSVMは3種類(SVC,LinearSVC,NuSVC)用意されています。
その中のSVC()を利用します。
次に、fit()ですが、fit()を使う事で学習(機械学習)が行えます。
fit()の第1引数に特徴量Xを与え、第2引数にラベルデータYを与え利用します。
続いて、作ったモデルに関して、予測をしてみましょう。
与えたものとしては、
がくの長さが1.4
がくの幅が1.8
花びらの長さが3.9
花びらの幅が0.5
のものはどの花かというものです。
print(clf.predict([[1.4, 1.8, 3.9, 0.5]]))
出力は0,1,2(花のラベル)のどれかになりますが、花のがくの長さと花のがくの幅、花の花弁の長さと花の花弁の幅を入力すると、花(のラベル)を予測が出来ました。
ここまでの全体のソースコードです。
"""
from sklearn import datasets
from sklearn import svm
# Irisの測定データの読み込み
iris = datasets.load_iris()
clf = svm.SVC()
clf.fit(iris.data, iris.target)
print(clf.predict([[1.4, 3.5, 5.1, 0.2], [6.5, 2.6, 4.4, 1.4], [5.9, 3.0, 5.2, 1.5]]))
"""
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
from sklearn.metrics import accuracy_score
# データの読み込み
iris = datasets.load_iris()
x, y = iris.data, iris.target
# トレーニングデータとテストデータに分ける
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)
# モデルの選択
model = svm.SVC()
# 学習
model.fit(x_train, y_train)
# 評価
pred = model.predict(x_test)
print(accuracy_score(y_test, pred))
# 学習済みモデルを使う
print(model.predict([[1.4, 3.5, 5.1, 0.2]]))
# 次のように、複数渡すことも可能
# print(model.predict([[1.4, 3.5, 5.1, 0.2], [6.5, 2.6, 4.4, 1.4], [5.9, 3.0, 5.2, 1.5]]))
まとめ
この章では、Scikit-learnを使ってアイリスデータセットの品種分類を行い機械学習プログラミングを体験しました。
今回扱ったテーマは、機械学習の教師あり学習の分類に関してのみです。
他にも、回帰などもありますので、もっと学びたい方は機械学習プログラミング入門編を進めてみてください。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!
