

AI・データサイエンス、
機械学習の実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データ
アナリストを目指したい - AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを無料体験してみませんか?


- 無料で120以上の教材を学び放題!
- Pythonやデータ分析、機械学習など
AI人材に必須のスキルを無料体験できる! - データ分析、AI開発の一連の流れを体験、実務につながる基礎スキルを習得!
1分で簡単!無料!
無料体験して特典を受け取る標準偏差とは
標準偏差とは、分散の平方根をとることによって計算される基本統計量の1つで、データの散らばりの度合いを示します。
標準偏差は以下の式で表されます。
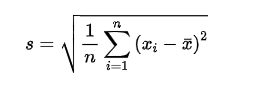
データの散らばりが大きいと標準偏差も大きくなります。また、散らばりが小さいと標準偏差は 0 に近づきます。文字式では、分散の文字式から2乗を取って、「s」や「σ」などと表されます。
標準偏差の求め方
標準偏差sを求めるには4つのステップを順に踏みます。
1. 平均値を求める
2. 偏差(数値 - 平均値)を求める
3. 分散(偏差の二乗平均)を求める
4. 分散の正の平方根を求める
標準偏差を求めるPythonプログラムは次のようになります。
scores = [90,80,40,60,90]
def mean(scores):
s = sum(scores)
N = len(scores)
mean = s // N
return mean
# 1. 平均値を求める
mean = mean(scores)
# 2. 偏差を求める
diff = []
for n in scores:
# 一人一人のスコアから平均値を引いたものをdiffリストの末尾に追加。
diff.append(n-mean)
print("偏差", diff)
# 3. 分散を求める
import numpy as np
# 分散(variance)
v = np.var(scores)
print("分散", v)
# 4. 分散の正の平方根を求める
std = np.std(scores)
print("標準偏差", std)分散(variance)とは
分散とは数値データのばらつき具合を表すための指標です。分散は、偏差(それぞれの数値と平均値の差)を二乗し、平均を取ることで求められます。
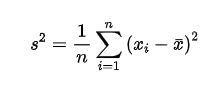
式を見ていただくと、分散は標準偏差を二乗した値になっています。
numpyのvar()を利用することで分散を表現できます。
import numpy as np
# 分散(variance)
v = np.var(scores)
print("分散", v) # 分散 376.0
scores = [90,80,40,60,90]
s = sum(scores)
N = len(scores)
mean = s // N
V1 = 0
for i in scores:
V1 = V1 + (1/len(scores)) * (i - mean)**2
print(V1) # 376.0出力結果
376.0
分散と標準偏差の違い
分散も標準偏差のどちらもデータの散らばりの度合いを示すたいですが、一般的にばらつきの大きさを示す際には、分散ではなく標準偏差を用います。
その理由として、分散は二乗しているため、長さのばらつきの場合に、長さの2乗の単位を持ってしまいます。
そこで標準偏差の場合、同じ単位で評価した方が感覚的に理解しやすいため、一般的にばらつきを表す場合には、分散の平方根をとった標準偏差を用います。
まとめ
この記事では、標準偏差とは何か、標準偏差の算出方法に関して学びました。
標準偏差は統計の書籍などで必ずと言って良いほど出てきますので、しっかりと理解して使いこなせるようにしましょう。
AI Academy Bootcampの「オンデマンド動画+チャットサポートプラン」は6ヶ月、機械学習エンジニアやデータサイエンティストからチャットにて、受講期間中、Pythonや統計学、機械学習など質問し放題です。
6ヶ月間質問し放題で、受講料も35,000円(税込)とお手軽にご受講頂けます。
(1日の受講費用換算で、194円でご受講頂けます。)
是非、いつでも質問し放題の環境で効率の良いAI学習を始めてみてください。



- 30時間以上の動画講座が見放題!
- 追加購入不要!
これだけで学習できるカリキュラム - (質問制度や添削プラン等)
充実したサポート体制!
1分で簡単!無料!

